

It is no secret that systems that use artificial intelligence (AI) are becoming increasingly important in our society. AI models are now used regularly to assist in making major decisions affecting people’s lives, including decisions such as medical diagnoses, financial decisions, job hiring calls, and more.
Yet despite the increasing integration of AI into society, we still struggle to explain why AI systems make the decisions they do. Why did the AI model decide that this brain scan is healthy while this other brain scan has a dangerous tumour? Why did ChatGPT decide to output this paragraph of text over this other one? These are important questions to be able to answer when creating beneficial AI systems. But before beginning to answer these questions, one of the first challenges to grapple with is a philosophical one. What should such an explanation even look like? What does it mean to explain a decision?

Hana Chockler, a professor at King's College London, has been combining insights from philosophy and computer science to pioneer new methods of explaining the decisions of AI systems. As Chockler explained at a recent event organised by the Newton Gateway to Mathematics and the Alan Turing Institute, she and her team have created a tool called ReX (short for Causal Responsibility-based Explanations) which explains why image-labelling AI models, called image classifiers, label images the way they do. Her work has immediate applications in medical imaging, allowing human doctors to better understand and even interact with AI systems which decide whether brain scans are healthy or not. Importantly, ReX works without having to know anything about the internal workings of the AI system, making it a general tool which can be applied not just to current AI systems but more complicated AI systems of the future as well.
Chockler started her career in an area of computer science known as formal verification. In this area, computer scientists use formal mathematical methods to say for certain whether programs actually do what we want them to do. For her PhD, Chockler took this one step further and studied how we could be sure the verification methods themselves checked what people wanted them to check. That is, even when the verification process says the program is correct, can we be sure the program is actually doing all the things we want? “In hindsight,” Chockler says, “this was already about explaining: how do we explain a positive answer? How do we explain no errors found?”
While in her PhD, a talk by computer scientist and philosopher Joseph Halpern caught Chockler’s attention. In philosophy, the question of explaining an outcome falls under the umbrella of causality. To explain an outcome, we must first know what it means to cause an outcome. Then, once we understand how outcomes are caused, we can explain an outcome by giving its cause.
At the time, Halpern was pioneering a new philosophical framework for defining causality he called actual causality. As she listened to Halpern talk, Chockler realised that the questions Halpern was solving with his framework were very similar to the questions she herself was working on. The only difference was that in her case, the outcomes that needed to be explained were the outputs of computer programs. “It was a lucky coincidence”, she says. “I was working on pure computer science problems at the time, and suddenly discovering that these philosophical concepts could actually be useful was a big paradigm shift for me.”
Chockler started working with Halpern, and together with her PhD supervisor Orna Kupferman, wrote a paper showing how the formal verification methods she was using in her PhD thesis could be reframed in terms of actual causality. Importantly for her future work, they also introduced how causality could be quantified, or given a numeric value. This idea of quantification would lay the groundwork for actual causality to become a powerful lens through which to explain the outputs of large AI models.
At the time though, nobody paid much attention to this work. It was 2002, and artificial intelligence was going through a period now dubbed the ‘AI drought’. “No community understood what we were talking about,” Chockler recalls. “Everybody was like, why were we suddenly bringing philosophy into it? What is this nonsense?”
“Of course, it looks funny now because everybody is talking about causality,” she says.

What is causality?
To understand how philosophers think about causality, imagine it’s raining outside and you’re walking home. When you arrive home, you’re wet from head to toe. What exactly does it mean to say that the rain caused you to get wet?
In 1739, Scottish philosopher David Hume introduced a first definition of causality, called counterfactual causality. Under counterfactual causality, Hume would say that the rain caused you to get wet because had there been no rain, you would not have gotten wet.

One problem with counterfactual causality is that it does not take into account the possibility of multiple overlapping causes. Consider instead the following world: You’re walking home, and it’s raining outside. On the way back, a car drives past through a puddle and splashes you. When you arrive home, you’re wet again.
In this world, had it not been raining, you still would have gotten wet from the car. Similarly, had the car not driven past, you still would have gotten wet from the rain. Thus neither the rain nor the car are counterfactual causes of you getting wet. But surely they did cause you to get wet!
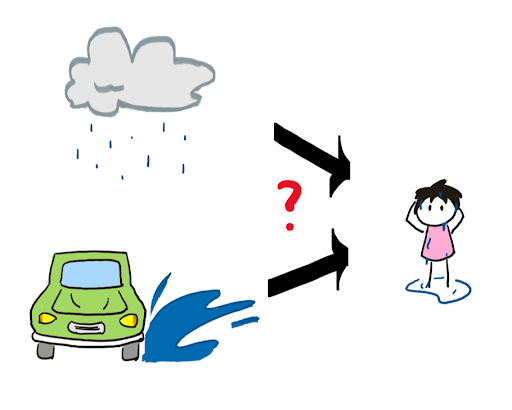
Actual causality
Actual causality addresses this problem by broadening our definition of causation. Under actual causality, we can imagine a contingent world which is the same as your original world in every way, except that there is no car. In this world, the rain is a counterfactual cause of you getting wet. Because we can imagine such a contingent world, we say rain is an actual cause of you getting wet. Similarly, we can imagine a contingent world which is the same in every way except that it is not raining. In this world, the car splashing you is a counterfactual cause of you getting wet. Thus, the car splashing you is also an actual cause of you getting wet in the original world.
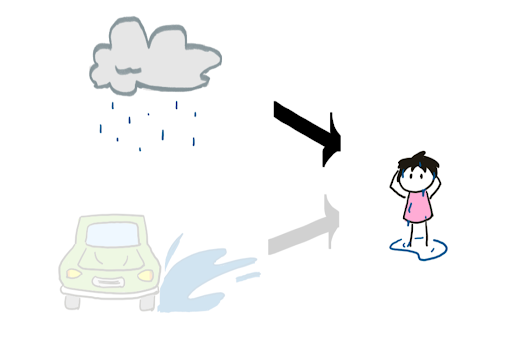
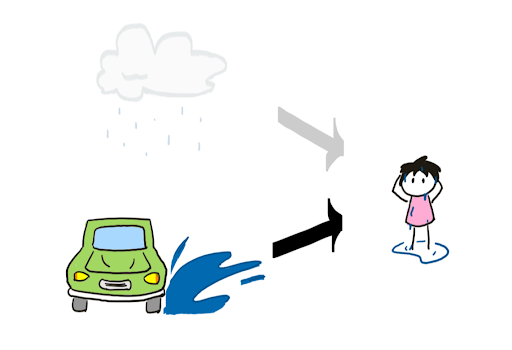
One major advantage of actual causality is that it allows the importance of causes to be quantified. In the first world without the car, the rain is entirely responsible for you getting wet. In the second world, we need to change a single thing in the contingent world (removing the car) for rain to be a counterfactual cause of you getting wet. In this case, rain would have 1⁄2 responsibility for you getting wet. We can imagine a world where 10 cars drive past and all splash you from head to toe. In this unlucky case, we would need to change 10 things in the contingent world for rain to be a counterfactual cause. Hence we would say that the rain was 1/(10+1) = 1/11 responsible for you getting wet. In general, if we need to alter n things in the contingent world for an event to be a counterfactual cause, we say the event has a responsibility of 1/(1+n) for the outcome.
By granting the ability to assign different degrees of responsibility to different causes, actual causality allows us to narrow our focus to just the most important causes of an event. This is important in large systems such as software engineering or AI models, where there may be many, many causes. (You can read more in Chockler and Halpern's 2004 paper that introduces the concept of responsibility.)
Analysing AI systems
One of the main benchmarks computer scientists test their AI tools on is the problem of image classification. Given an image, how can an AI system tell what its contents are?
Let’s say the AI decides that the image is of a peacock. Why did it make this decision? A human might give the explanation that it was a peacock because of its blue and green patterned tail. Chockler and her colleagues have developed their tool ReX to obtain a similar sort of causal explanation from an AI model. For an AI model, a causal explanation is any part of the original image which is just large enough to identify the content of the original image, but no larger. In the case of peacock pictures, an AI might explain that it decided the image was of a peacock because the pixels comprising the tail were sufficient for such a decision, but any smaller subset of pixels would be inconclusive.


An image of a peacock, and a causal explanation for why the image was classified as a peacock. (Image by Hana Chockler - used with permission)
ReX obtains such a causal explanation from the AI model by feeding it many images which are ever so slightly altered from the original. By looking at how the AI classifies each of the slightly altered images, ReX can get a good estimate as to how much each pixel of the original image affects the overall decision by the AI. In the language of actual causality, it considers many different nearby contingent worlds to estimate the responsibility of each original pixel. After doing this for every pixel, it then selects just enough of the most responsible pixels so that the overall image is classified as a peacock.
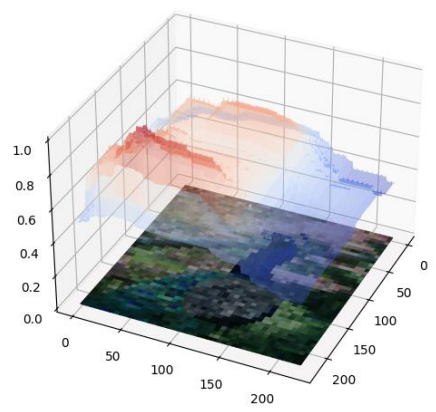
Because actual causality is a general philosophical framework which applies to any causal system, ReX works without having to know anything about the internal workings of the AI system. No matter what the AI system looks like on the inside, as long as we can give it inputs and read the corresponding outputs, ReX allows us to obtain an explanation from the AI. Because of this, it can be applied to AI systems which are too large or complicated for us to understand directly.
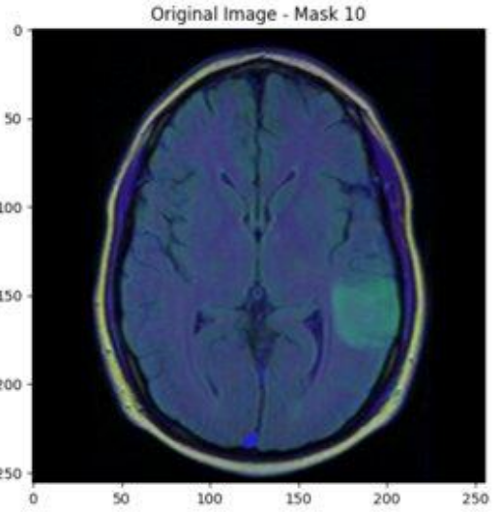
One immediate use of ReX is in the field of medical imaging. When a patient with a suspected brain tumour gets an MRI, an AI system on the other side will automatically classify the scan as either containing a tumour or not. If the system believes the scan has a tumour, then it goes immediately to the physician. If not, the scan will still go to the physician, but maybe it will only get to them in a couple days.
With ReX, the AI system can say “the tumour is over here!” which helps the physician diagnose much faster. ReX can also explain the absence of a tumour in an image. Since tumours tend to show up as a different colour from healthy tissue, ReX can return a grid of healthy tissue-coloured pixels and say, I know that all this tissue is healthy, and no tumour can fit in between all this healthy tissue. Hence there cannot be a tumour in this brain scan. If the physician disagrees, they can tell the AI to check closer in suspicious areas, supporting a dialogue between the physician and the AI system. (You can read more about this work in this 2023 paper by Chockler and her colleagues.)
What next?
Although her work straddles the line between philosophy and computer science, Chockler maintains that she is at heart a practical person. “I’m interested in things that we can build, that we can verify, and that we can prove,” she says. One of the next big goals of her team is to apply their techniques to large language models such as ChatGPT.
With language models such as ChatGPT, there is a challenge not present in image classifiers: language is very heavily context-dependent. In a picture of a cat, you can cover up the background and the picture will still be of a cat, allowing you to find small subsets of the image which still stand in for the entire thing. In a sentence or a paragraph however, covering up a single “no” may completely reverse the entire meaning of the text. Because of this, the idea of a minimal causal explanation is hard to directly carry over. “We are not there yet,” Chockler says, “but we’ve got a lot of people and we are very excited for what comes next.”
About this article
Hana Chockler is Professor of Computer Science at Kings College London. You can read more about the work discussed in this article in her 2021 paper (with Daniel Kroening and Youcheng Sun) introducing an approximation for causal explanations, and in her 2024 paper with Joseph Halpern that formalises causal explanations.
Chockler was one of the speakers at Generative AI and Applications: Next Steps, an Open for Business event that was part of the longer research programme on diffusions in machine learning, jointly organised by the Alan Turing Institute in London and the Isaac Newton Institute for Mathematical Sciences in Cambridge.
Justin Chen is currently studying for his masters in mathematics at the University of Cambridge and was an intern with Plus during the summer of 2024. He interviewed Hana Chockler in July 2024.
This article was produced as part of our collaborations with the Isaac Newton Institute for Mathematical Sciences (INI) and the Newton Gateway to Mathematics.
The INI is an international research centre and our neighbour here on the University of Cambridge's maths campus. The Newton Gateway is the impact initiative of the INI, which engages with users of mathematics. You can find all the content from the collaboration here.
![]()
