

Claude Shannon.
It's not very often that a single paper opens up a whole new science. But that's what happened in 1948 when Claude Shannon published his Mathematical theory of communication. Its title may seem strange at first — human communication is everything but mathematical. But Shannon wasn't thinking about people talking to each other. Instead, he was interested in the various ways of transmitting information long-distance, including telegraphy, telephones, radio and TV. It's that kind of communication his theory was built around.
Shannon wasn't the first to think about information. Harry Nyquist and Ralph Hartley had already made inroads into the area in the 1920s (see this article), but their ideas needed refining. That's what Shannon set out to do, and his contribution was so great, he has become known as the father of information theory.
Information is surprise
Shannon wanted to measure the amount of information you could transmit via various media. There are many ways of sending messages: you could produce smoke signals, use Morse code, the telephone, or (in today's world) send an email. To treat them all on equal terms, Shannon decided to forget about exactly how each of these methods transmits a message and simply thought of them as ways of producing strings of symbols. How do you measure the information contained in such a string?
It's a tricky question. If your string of symbols constitutes a passage of English text, then you could just count the number of words it contains. But this is silly: it would give the sentence "The Sun will rise tomorrow" the same information value as he sentence "The world will end tomorrow" when the second is clearly much more significant than the first. Whether or not we find a message informative depends on whether it's news to us and what this news means to us.
Shannon stayed clear of the slippery concept of meaning, declaring it "irrelevant to the engineering problem", but he did take on board the idea that information is related to what's new: it's related to surprise. Thought of in emotional terms surprise is hard to measure, but you can get to grips with it by imagining yourself watching words come out of a ticker tape, like they used to have in news agencies. Some words, like "the" or "a" are pretty unsurprising; in fact they are redundant since you could probably understand the message without them. The real essence of the message lies in words that aren't as common, such as "alien" or "invasion".
This suggests a measure of surprise for each word: the frequency with which it appears in the English language. For example, the most frequent word in the 100 million word British National Corpus is the word "the", appearing, on average, 61,847 times in a million words. The word "invasion" appears, on average, only 19 times per million words, while "alien" is not even listed, presumably because it is so rare.

Unsurprised women watching the ticker tape in 1918.
You could simply measure the amount of surprise you feel when a word occurs by the number of times it occurs per million words in some large volume of English text. But this would be missing a trick. The word "invasion" is pretty surprising when it follows the word "alien", but less surprising when it follows the word "military". Perhaps surprise should be measured, not only in terms of the overall frequency of a word, but also in terms of the word that came before it (you can do this by looking at the frequency of pairs of words in large body of text). To capture even more of the structure within the English language, you could base your surprise measure on the frequency of triples, quadruples, quintuples, and so on.
Producing gibberish
Shannon appears to have had some fun playing around with this idea. On page 7 of A mathematical theory of communication he reproduced a string of words that were picked at random, independently of each other and with a probability reflecting their frequency:
REPRESENTING AND SPEEDILY IS AN GOOD APT OR COME CAN DIFFERENT NATURAL HERE HE THE A IN CAME THE TOOF TO EXPERT GRAY COME TO FURNISHES THE LINE MESSAGE HAD BE THESE.
He also produced a sentence in which the probability of a word occurring depended on its predecessor, based on the frequencies of pairs of words:
THE HEAD AND IN FRONTAL ATTACK ON AN ENGLISH WRITER THAT THE CHARACTER OF THIS POINT IS THEREFORE ANOTHER METHOD FOR THE LETTERS THAT THE TIME OF WHO EVER TOLD THE PROBLEM FOR AN UNEXPECTED.
Both sentences are utterly meaningless, but the second looks just that little bit more like an English sentence than the first: there are whole strings of words that actually make sense.
But Shannon's games with random words had another purpose too. If you picked a more sophisticated probability distribution for your words, one that picks up on more structure within the English language, you could presumably approximate that language much more closely. Conversely, you could think of any device that produces strings of words, like the ticker machine, as a stochastic process. Forget about the person who is sending the message and the meaning they want to convey and simply imagine the machine picking words at random, based on a probability distribution that closely reflects the structure of the English language. To formalise things even further, forget about words and think of the machine picking individual symbols according to a certain probability distribution. This way, we can measure surprise not only for languages spoken by people, but also for strings of 0s and 1s produced by a computer, or for smoke signals sent in the forest.
Calculating surprise

Most people would be surprised by an alien invasion.
This line of thinking led Shannon to consider an idealised situation. Suppose there’s a random process which produces strings of symbols according to a certain probability distribution, which we know. Assume, for the moment, that each symbol is picked independently of the one before. We could simply define the surprise 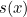 associated to a single symbol
associated to a single symbol  as the reciprocal of its probability
as the reciprocal of its probability 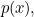 so
so 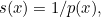 reflecting the fact that the less probable a letter, the more surprised we are at seeing it. But this definition leads to a problem. The probability of seeing two symbols and
reflecting the fact that the less probable a letter, the more surprised we are at seeing it. But this definition leads to a problem. The probability of seeing two symbols and 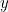 occurring one after the other, if they are picked independently, is the product of the individual probabilities,
occurring one after the other, if they are picked independently, is the product of the individual probabilities,  If we measure surprise by reciprocals of probabilities, then the surprise associated to the two symbols appearing together is the product of the individual surprises
If we measure surprise by reciprocals of probabilities, then the surprise associated to the two symbols appearing together is the product of the individual surprises
![\[ s(xy) = \frac{1}{p(xy)} = \frac{1}{p(x) \times p(y)} = \frac{1}{p(x)} \times \frac{1}{p(y)} = s(x) \times s(y). \]](/MI/56c09cb543ec31341504b1627e490cb7/images/img-0007.png) |
However, intuitively the surprise of seeing followed by should be the sum of the individual surprises. You can convince yourself of this by imagining that I tell you two facts that aren’t related to each other, for example "the cat is black" and "today is Monday". Because they are unrelated the total amount of surprise contained of both sentences is the information of the first plus the information of the second. A function that does make surprises additive is the logarithm of the reciprocal of probabilities:
![\[ s(x) = \log {\left(1/p(x)\right)}. \]](/MI/56c09cb543ec31341504b1627e490cb7/images/img-0008.png) |
We still have the inverse relationship (the less probable a symbol the greater the surprise) and the surprise of seeing and appear one after the other is now
![\[ s(xy) = \log {\left(1/(p(x)p(y)\right))} = \log {\left(1/p(x)\right)} + \log {\left(1/p(y)\right)} = s(x)+s(y). \]](/MI/56c09cb543ec31341504b1627e490cb7/images/img-0009.png) |
According to this definition the surprise associated to seeing a longer string is simply the sum of the individual surprises.
The logarithm of inverse probability also has some other properties that sit well with our intuition of surprise. For example, if the machine always produces the same letter 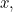 so
so 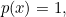 then we shouldn’t be surprised at all to see and indeed in this case the surprise is
then we shouldn’t be surprised at all to see and indeed in this case the surprise is 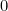 :
:
![\[ s(x) = \log {1} = 0. \]](/MI/56c09cb543ec31341504b1627e490cb7/images/img-0013.png) |
Thus, Shannon decided to stick to the logarithm as a measure of surprise. It doesn't really matter which base you choose for the logarithm — the choice varies the exact surprise value for each symbol, but doesn't change the way they interact. (Note that if there are 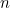 symbols, all with equal probability
symbols, all with equal probability 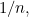 then the surprise of each is exactly Hartley's measure of information we explored in the previous article.)
then the surprise of each is exactly Hartley's measure of information we explored in the previous article.)
Average surprise
This sorts out the amount of surprise, which we've related to the amount of information, of a string of symbols produced by our machine. For reasons that will become clear later, we can also calculate the expected amount of surprise the machine produces per symbol. This is akin to an average, but takes into account that symbols with higher probabilities occur more often, and should therefore contribute more to the average than those with low probabilities (see here to find out more about expected values).
If our machine produces 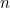 letters,
letters, 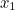 ,
, 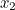 ,
, 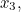 etc up to
etc up to 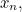 with probabilities
with probabilities 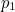 ,
,  ,
, 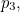 etc up to
etc up to 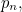 then the expected value of surprise is
then the expected value of surprise is
![\[ H = p_1 \log {\left(1/p_1\right)} + p_2 \log {\left(1/p_2\right)} + p_3 \log {\left(1/p_3\right)} + ... + p_ n \log {\left(1/p_ n\right)}. \]](/MI/7636d6683acba19bb6b06a2377f68479/images/img-0010.png) |
By the rules for the logarithm, we know that 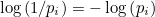 so we can write
so we can write  as
as
![\[ H = -( p_1 \log {p_1} + p_2 \log {p_2} + p_3 \log {p_3} + ... + p_ n \log {p_ n}). \]](/MI/7636d6683acba19bb6b06a2377f68479/images/img-0013.png) |

The concept of entropy was first developed in the context of thermodynamics, the study of heat.
If you know some physics then this expression might look familiar. It looks exactly the same as a quantity called entropy which physicists had defined around seventy years earlier to understand the behaviour of liquids and gases (find out more in this article). This parallel wasn't lost on Shannon. He called the measure of average information 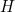 defined above the entropy of the machine. It depends only on the probability distribution of the possible symbols, the exact workings of the mechanism producing it don't matter. Entropy is a truly universal measure of information.
defined above the entropy of the machine. It depends only on the probability distribution of the possible symbols, the exact workings of the mechanism producing it don't matter. Entropy is a truly universal measure of information.
(If you've been paying attention, you might have noticed one issue. To define our measure of surprise we assumed that symbols were being picked independently of each other. Earlier, however, we said that to simulate a real message written, say, in English, the probability of a symbol being picked should depend on the symbol or, even better, symbols that came before it. But this isn't a problem. There's a way of picking those dependent probabilities apart to get many independent distributions — the overall entropy is then an average of the component ones. See Shannon's paper to find out more.)
An example
Let’s look at an example. Suppose the machine can only produce two symbols, an 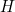 and a
and a 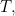 and that it picks them with equal probability of
and that it picks them with equal probability of 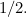 It might do so by flipping a fair coin, hence the choice of the symbols. The entropy of this probability distribution is
It might do so by flipping a fair coin, hence the choice of the symbols. The entropy of this probability distribution is
![\[ H = 1/2\log {\left(2\right)} + 1/2\log {\left(2\right)} = \log {\left(2\right)}. \]](/MI/a446e0c9c93fa5211f48e65b4111b09a/images/img-0004.png) |
Choosing the base of the logarithm to be 2, this gives us a nice round value:
![\[ H = \log _2{\left( 2 \right)} = 1. \]](/MI/a446e0c9c93fa5211f48e65b4111b09a/images/img-0005.png) |
Now suppose that the coin is crooked, so it come up heads 90% of the time. This means that 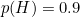 and
and 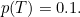 The entropy now becomes
The entropy now becomes
![\[ H = 0.9\log _2{\left(1/0.9 \right)} + 0.1\log _2{\left(1/0.1 \right)} = 0.469. \]](/MI/a446e0c9c93fa5211f48e65b4111b09a/images/img-0008.png) |
It’s lower than the entropy of the fair coin and this makes sense: knowing that the coin is crooked, we can guess the outcome correctly around 90% of time by tipping on H. Therefore, on average, our surprise at seeing the actual outcome isn’t that great — it’s definitely less than for a fair coin. Thinking of surprise as measuring the information, this tells us that the average amount of information inherent in the machine printing one symbol is less than the corresponding number for the fair coin.
But why on Earth would you want to calculate the average amount of surprise (or information) per symbol? It turns out that Shannon's entropy also has a very concrete interpretation that is very relevant to the modern world: it measures the minimum number of bits — that's 0s and 1s — needed to encode a message. To find out more, see the next article.
About this article
This article is part of our Information about information project, run in collaboration with FQXi. Click here to find out about other ways of measuring information.
Marianne Freiberger is co-editor of Plus. She would like to thank Scott Aaronson, a computer scientist at the Massachusetts Institute of Technology, for a very useful conversation about information. And she recommends the book Information Theory: A Tutorial Introduction by James V. Stone as a mathematical introduction to the subject.
Comments
Shannon information vs Jane Austen information
Many highly intelligent people fail to notice that Shannon's concept of information as a measurable property of strings of symbols is very different from the much older concept of information as semantic content (or meaning), which is part of our everyday language and was used frequently by Jane Austen in her novels over a century before Shannon introduced his concept. In talking about intelligence and use of information by organisms (including humans) we are almost always referring to Austen information. See https://www.cs.bham.ac.uk/research/projects/cogaff/misc/austen-info.html for more detail.