
Everyone knows that it is easy to make mistakes when lots of numbers are involved - and I'm not talking about all those slip-ups that occur in exams. It is so easy to get a few digits of a bank account number mixed up, or for fingers to slip on a keyboard and enter the wrong numbers. Imagine the consequences of these errors: things might go your way, you might get access to Bill Gates's bank account, for example, but the chances of that are relatively slim. Alternatively, if a bar code gets printed wrongly, you might end up paying the price of a bottle of champagne for your carton of apple juice or if the number on your airline ticket is wrong, who knows where you or your luggage might end up? Luckily, there are schemes in place to detect, and in some cases even correct, such errors almost immediately.
Error Detection
An error-detecting code is a way of transmitting data - a number, say - so that most common mistakes will be detected at once, before they can cause any damage. A very simple example would be to transmit the whole number twice. This is grossly inefficient, however. It doubles the length of the number, and even then, if an error is detected, leaves us in the dark about the correct number - was the first transmission correct, or the second? The code performs error detection, but not error correction. We'll see in this article that there are far more efficient codes available.
There are many different methods of error detection. Generally, the number to be transmitted is followed by a number of check digits - most often one for simple error detection, but if we are to do error correction too, at least two will be needed. Then when the number is transmitted, another calculation can be done at the receiving end to check that the received number (including the check digit) is valid. We shall look at three schemes used for calculating check digits: modular schemes, permutation schemes and noncommutative schemes, and at some examples of where they are used.
Modular Arithmetic
Modular arithmetic involves working with the remainders generated by division. For example, if 36 is divided by 7, the remainder is 1. Using modular arithmetic notation, this can be written as
![\[ 36 = 1(\mbox{mod} 7). \]](/MI/635a286a90f9fa533c5038a704268cfa/images/img-0001.png) |
Similarly,
![\[ 47 = 11(\mbox{mod} 12), \]](/MI/635a286a90f9fa533c5038a704268cfa/images/img-0002.png) |
![\[ 62 = 2(\mbox{mod} 10), \]](/MI/635a286a90f9fa533c5038a704268cfa/images/img-0003.png) |
and in general
![\[ p = q (\mbox{mod} N) \mbox{ if }p-q \mbox{ is a multiple of the integer }N. \]](/MI/635a286a90f9fa533c5038a704268cfa/images/img-0004.png) |
For example,
![\[ 47 = 11(\mbox{mod} 12) = -1(\mbox{mod} 12), \]](/MI/635a286a90f9fa533c5038a704268cfa/images/img-0005.png) |
since
![\[ 47 - (-1) = 48 = 12 \times 4. \]](/MI/635a286a90f9fa533c5038a704268cfa/images/img-0006.png) |
The simplest check digit schemes use the code number itself as part of a modular arithmetic operation. For example, take a code number,  , create a check digit,
, create a check digit, 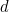 , for this number such that:
, for this number such that:
![\[ c = d (\mbox{mod} N) \]](/MI/635a286a90f9fa533c5038a704268cfa/images/img-0009.png) |
for some fixed modulus 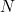 .
.
For example, suppose the number to transmit is 12345 and we have chosen the modulus 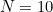 . The check digit would be 5, and we would transmit it after the digits of the number: 123455. If the receiver received, say, 123445, they would know there had been a mistake since 12344 is not equal to 5 (mod 10). Obviously this will only catch an error in the last digit of the number (or in the check digit), so the choice of as modulus was particularly poor. We’ll see in the next section that a different modulus can catch a fairly high proportion of the most common errors, even using this simple scheme. In general, though, it will at most tell us that there has been an error; it will not help us find where the error was, and cannot be error-correcting.
. The check digit would be 5, and we would transmit it after the digits of the number: 123455. If the receiver received, say, 123445, they would know there had been a mistake since 12344 is not equal to 5 (mod 10). Obviously this will only catch an error in the last digit of the number (or in the check digit), so the choice of as modulus was particularly poor. We’ll see in the next section that a different modulus can catch a fairly high proportion of the most common errors, even using this simple scheme. In general, though, it will at most tell us that there has been an error; it will not help us find where the error was, and cannot be error-correcting.
There are various different errors that can occur when numbers are written, printed or transferred in any manner. Different methods of assigning check digits are better at detecting certain kinds of errors than others. The most common types of errors that occur in practice and their frequencies, according to one study, are as follows:
| Error type | Form | Relative frequency |
| single error | a replaced by b | 79.1% |
| transposition of adjacent digits | ab replaced by ba | 10.2% |
| jump transposition | abc replaced by cba | 0.8% |
| twin error | aa replaced by bb | 0.5% |
| phonetic error | a0 swapped with 1a a = 2,...,9 |
0.5% |
| jump twin error | aca replaced by bcb | 0.3% |
Another common type of error not mentioned here is accidental insertion or deletion of characters. In the cases we will consider, the number will have a fixed length, so insertions and deletions will be automatically detected.
We are now ready to see how this is all put into practice so let's bring on our first example ...
Airline tickets
Airline tickets have a ten-digit serial number followed by a check digit. This check digit is calculated using the modular scheme discussed above, with modulus 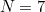 .
.
For example, a ticket might have serial number 3387972544. Since this number equals 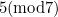 , the check digit is 5. The number is printed on the ticket with the check digit: 33879725445.
, the check digit is 5. The number is printed on the ticket with the check digit: 33879725445.
This is quite a primitive method. Is it really any good at detecting errors? From the list of relative frequencies of errors, we can see that far the most important errors to detect are single-digit errors and transpositions of adjacent digits. Let’s see how well this modular scheme does in these cases.
Single digit errors
As we’ve just seen, an airline ticket has a ten-digit serial number, followed by a check digit. Let’s call the serial number  , and the check digit
, and the check digit 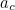 . Then is calculated so that
. Then is calculated so that
![\[ a = a_ c (\mbox{mod} 7). \]](/MI/f85ee5a9bc280d2e76beabdea0b74e2e/images/img-0003.png) |
The number itself consists of ten digits; let’s call them 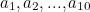 . A single-digit error consists of replacing one of these digits
. A single-digit error consists of replacing one of these digits 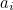 with some other digit,
with some other digit, 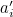 , say, giving a new (and wrong) serial number
, say, giving a new (and wrong) serial number 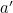 , or possibly the right serial number but the wrong check digit.
, or possibly the right serial number but the wrong check digit.
Will a single-digit substitution in the serial number show up - that is, will it change the value of 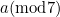 ? The answer is yes, as long as the substituted digit itself has changed (mod 7). (You might like to try to convince yourself that this is because 7 has no factors in common with 10, the base in which the numbers are expressed.)
? The answer is yes, as long as the substituted digit itself has changed (mod 7). (You might like to try to convince yourself that this is because 7 has no factors in common with 10, the base in which the numbers are expressed.)
In other words, this code will catch most single-digit substitutions. It will miss those where 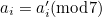 , i.e. it will miss the errors
, i.e. it will miss the errors 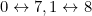 and
and 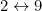 in the serial number. For example, suppose the example ticket number above were copied as 33879795445. A "2" has been incorrectly copied as a "9". A check will verify that
in the serial number. For example, suppose the example ticket number above were copied as 33879795445. A "2" has been incorrectly copied as a "9". A check will verify that 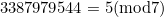 , and so the error will be missed.
, and so the error will be missed.
Each digit could be any of the 10 digits 0-9; a substitution could replace it with any of the other 9 digits; and there are 10 digits in all. The number of possible substitutions is thus 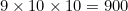 , and 60 of those will be missed.
, and 60 of those will be missed.
Other possible single digit errors that could occur involve the check digit. The numbers 7,8 and 9 are not allowed remainders, so there are only 7 valid check digits, {0,…,6}. This means there are 63 possible errors, but all of them would be detectable.
Therefore the single error detection rate is 903/963 or 93.8%.
Throughout these calculations, we have assumed that all errors have the same probability of being introduced (ie 5 being substituted for 6 is as likely as 1 being substituted for 9). In practice, this is unlikely to be true, but there is not enough data available to calculate more accurate probabilities.
Transposition of adjacent digits
Now we look at transpositions (where two adjacent digits 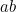 are transposed to
are transposed to 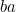 ). Among the first 10 digits there are 9 pairs that could be transposed, and for any pair there are 100 possibilities. If the digits of a pair are the same, transposing them won’t make any difference, so for each pair there are 90 possibilities that could lead to an error. The error will be undetectable if the digits transposed are equal mod 7 - namely if they are 07, 70, 18, 81, 29 or 92. So there are 6 undetectable transpositions out of each 90. The total number of possible errors is 810, of which 54 would not be detected.
). Among the first 10 digits there are 9 pairs that could be transposed, and for any pair there are 100 possibilities. If the digits of a pair are the same, transposing them won’t make any difference, so for each pair there are 90 possibilities that could lead to an error. The error will be undetectable if the digits transposed are equal mod 7 - namely if they are 07, 70, 18, 81, 29 or 92. So there are 6 undetectable transpositions out of each 90. The total number of possible errors is 810, of which 54 would not be detected.
For the final pair (the 10th digit and the check digit), there are 70 possibilities, since the check digit cannot be 7, 8 or 9. Of these, 63 would lead to an error if the digits were transposed, but all such errors would be detectable.
In all, of 873 possible transposition errors, only 54 would be missed, giving a detection rate of 93.8%.
These error detection rates are quite high, but could they be higher? Let’s see if better results can be obtained simply by using a different value for  . The choice of modulus 9 is often used: for example, the identity numbers on US Postal Orders is 10 digits long, and consists of a 9-digit serial number and a check digit equal to the serial number’s mod-9 remainder. If we were to do the calculations for a number of the same length as that used in the example above (10 digits followed by a check digit), we would find the single error detection rate to be 98.0%, which is slightly higher than with a modulus of 7. However, the detection rate for the transposition of adjacent digits is 9.1%, which is much lower. (An error will only be caught if it involves the check digit.)
. The choice of modulus 9 is often used: for example, the identity numbers on US Postal Orders is 10 digits long, and consists of a 9-digit serial number and a check digit equal to the serial number’s mod-9 remainder. If we were to do the calculations for a number of the same length as that used in the example above (10 digits followed by a check digit), we would find the single error detection rate to be 98.0%, which is slightly higher than with a modulus of 7. However, the detection rate for the transposition of adjacent digits is 9.1%, which is much lower. (An error will only be caught if it involves the check digit.)
European Article Numbering Code
Barcodes are familiar to most as they are found on the majority of the things we buy. Look at a barcoded item, and underneath the barcode itself there is a string of digits, the last of which is a check digit. These use a slightly more complicated scheme of assigning check digits, involving a "weighted sum" of the digits of the number.
To calculate a "weighted sum" of a series of numbers, we choose a fixed sequence of numbers called ıweights. Each number in the series is multiplied by the corresponding weight before being added to the total. For example, suppose we have chosen weights (1,2,3), and the series is (7,8,9). The weighted sum is
![\[ 1\times 7+2\times 8+ 3\times 9 = 7 + 16 + 27 = 50. \]](/MI/b84894c2dfb144ea8883da22bc537da4/images/img-0001.png) |
Barcodes in Europe follow the European Article Numbering Code (EAN) format. There are two versions, EAN-8 and EAN-13, which use 8 and 13 digits respectively. For both, the weights chosen are alternate 1’s and 3’s. We’ll look at the 8-digit version (the calculations for the 13-digit version are very similar).
Since the last digit is a check digit, only 7 of the 8 digits actually encode information.

Sample of a 13-digit EAN bar code.
The format uses a modulus 10 scheme, with check digits (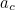 ) defined by
) defined by
![\[ a_ c = - (a_1, a_2,\dots , a_6, a_7).(3, 1, 3, 1, 3, 1, 3)(\mbox{mod} 10). \]](/MI/24e06769a9c501be07e02ff91dd65b49/images/img-0002.png) |
For example, if we start with the number 1234567 in the EAN-8 scheme, then our check digit is
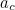 |
 |
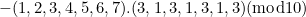 |
|||
 |
|
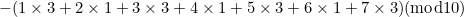 |
|||
|
|
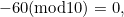 |
which makes the full bar code number 12345670.
Again, we must worry about how effective this scheme is in detecting errors.
Single error detection rate
If a digit 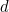 whose weight is 1 is changed to
whose weight is 1 is changed to  , the weighted sum will change by
, the weighted sum will change by 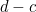 . The error will go undetected only if
. The error will go undetected only if 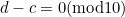 . But this happens only when
. But this happens only when 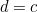 , in which case there has not been an error after all, so all errors of this kind are caught.
, in which case there has not been an error after all, so all errors of this kind are caught.
What if the weight were 3? Then the error would be undetected if 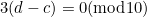 . But again, this cannot happen unless . Thus, this method has a 100% single error detection rate.
. But again, this cannot happen unless . Thus, this method has a 100% single error detection rate.
Transposition of adjacent digits detection rate
Suppose two adjacent digits, 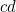 , are transposed to
, are transposed to 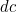 . If
. If  ’s weight is 3 (hence
’s weight is 3 (hence 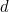 ’s weight is 1), the weighted sum is changed by
’s weight is 1), the weighted sum is changed by
![\[ (3c + d) - (c + 3d) = 2 (c-d) \]](/MI/016b8fe60129a392b2b2a17701f43436/images/img-0005.png) |
which will be detected unless 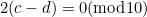 , which can happen only if and differ by 5. The same would have applied if had been weighted by 1 and by 3.
, which can happen only if and differ by 5. The same would have applied if had been weighted by 1 and by 3.
As a result, the transpositions that will go undetected must involve 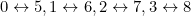 and
and 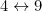 . So, 10 transpositions are undetectable.
. So, 10 transpositions are undetectable.
There are 100 possibilities for each pairing, and the transposition of 90 of these would result in an error. Therefore the detection rate is 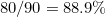 .
.
International Standard Book Number (ISBN)
Almost every book published has an International Standard Book Number (ISBN) printed on it. The ISBN is a nine-digit code with a tenth digit which is - you guessed it - a check digit. ISBNs use a weighted modulus-11 scheme. This has the great advantage that it detects all single digit errors and transpositions. The disadvantage is that the remainder can be 10, which is not a digit. A remainder of 10 is represented as X in ISBNs. The fact that the resulting "number" must occasionally include a non-digit is a little untidy, and for some applications it would be highly undesirable. For example, some automatic credit-card booking systems require you to dial your credit card number on the keypad of your phone. This would work badly if the card number was occasionally liable to include a non-digit.
However, it is important to catch mistyped card numbers. We'll see later that credit cards use a very clever scheme whose detection rate for single errors and transpositions is better than the airline ticket and EAN schemes we've looked at so far.
Choosing the optimum modulus for a weighted scheme
The effectiveness of this type of scheme obviously depends quite a lot on the weights and the modulus. What conditions are needed for errors to be detected, and is there a best choice for the modulus?
Single digit errors
If a digit  is replaced by a different digit
is replaced by a different digit 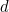 , the error will be undetected when
, the error will be undetected when  multiplied by the appropriate weight,
multiplied by the appropriate weight, 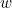 , is a multiple of
, is a multiple of 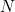 . This will happen less often if has no factors in common with ; perhaps you can see now why the barcode system uses weights of 1 and 3 (rather than 1 and 2, say). Other than that, the larger is, the better. Once is at least 10, all such errors will be caught if has no common factor with any of the weights.
. This will happen less often if has no factors in common with ; perhaps you can see now why the barcode system uses weights of 1 and 3 (rather than 1 and 2, say). Other than that, the larger is, the better. Once is at least 10, all such errors will be caught if has no common factor with any of the weights.
Transpositions
On the other hand, if adjacent digits and
and 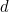 are transposed, the tranposition will go undetected when
are transposed, the tranposition will go undetected when  multiplied by the difference between their weights is a multiple of
multiplied by the difference between their weights is a multiple of 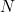 . We'd like to arrange for successive weights to have no factor in common with . Unfortunately, if is even (say
. We'd like to arrange for successive weights to have no factor in common with . Unfortunately, if is even (say 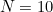 ), and if as above the weights themselves have no common factor with (so they're all odd), then their differences must be even. Generally, the more prime is, the better life will be. This is why, if the serial number has digits 0-9, we needed a modulus of at least 11 before we could be certain of catching all single-digit errors and all transposition errors. However, as we saw, a scheme that uses
), and if as above the weights themselves have no common factor with (so they're all odd), then their differences must be even. Generally, the more prime is, the better life will be. This is why, if the serial number has digits 0-9, we needed a modulus of at least 11 before we could be certain of catching all single-digit errors and all transposition errors. However, as we saw, a scheme that uses 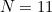 has to choose some method of coping with the possibility of the remainder being 10.
has to choose some method of coping with the possibility of the remainder being 10.
Permutations
A permutation (of a set of digits, say) is a rule for systematically replacing one digit with another. You have probably met them in the form of substitution ciphers, such as the one where each letter of the alphabet is shifted up one, so "IFMMP" means "HELLO". This particular permutation is just one long cycle - A goes to B, B goes to C, and so on all the way to Z which goes back to A. Like any permutation, it can be applied more than once; for instance if it is applied twice to A, the result is C.
We can write any permutation by writing down the cycles it contains. For instance, one permutation of the digits 0-9 could be written (02468)(1)(3)(5)(7)(9), showing that even numbers are cycled round (0 goes to 2, 2 goes to 4, etc), and all odd numbers are unchanged. We can call the permutation 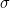 , so in this case,
, so in this case, 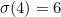 ,
, 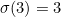 , and so on.
, and so on.
Credit cards
Credit cards use an error-detecting scheme that was developed by IBM. It uses the permutation
![\[ \sigma =(0)(124875)(36)(9). \]](/MI/574d5694fd5d696121fce83ebcaca16a/images/img-0001.png) |
In other words 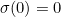 ,
, 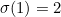 ,
, 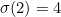 , etc. Notice that
, etc. Notice that 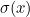 is always equal to
is always equal to 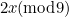 .
.
In a 16 digit credit card number, the final digit is the check digit. Let the credit card number be 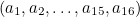 , with
, with 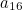 being the check digit. Then
being the check digit. Then
![\[ a_{16} = -[\sigma (a_1) + a_2 + \sigma (a_3) + a_4 + ... + a_{14} + \sigma (a_{15})] (\mbox{mod} 10). \]](/MI/574d5694fd5d696121fce83ebcaca16a/images/img-0009.png) |
Note that in this example the permutation was applied to 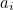 where
where 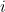 is odd (
is odd (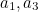 etc), because there is an odd number of digits excluding the check digit. Had this scheme been used on a number with an even number of digits excluding the check digit, the permutation would have been applied to where was even.
etc), because there is an odd number of digits excluding the check digit. Had this scheme been used on a number with an even number of digits excluding the check digit, the permutation would have been applied to where was even.
This scheme will catch all single-digit errors. For example if digit is changed from  to
to 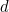 , and is even, the remainder will change by
, and is even, the remainder will change by 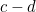 , which is non-zero (and is, of course, smaller than the modulus
, which is non-zero (and is, of course, smaller than the modulus 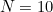 ). If is odd, it will change by
). If is odd, it will change by 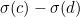 . This is again non-zero:
. This is again non-zero: 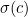 cannot be equal to
cannot be equal to 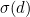 if
if 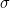 is a permutation.
is a permutation.
How about transpositions? If two adjacent digits and are transposed, one of them must have the permutation applied - say . The remainder will be unchanged only if 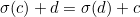 . Since
. Since 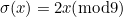 , this happens only when
, this happens only when 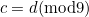 , that is, only when and are 0 and 9 (in either order).
, that is, only when and are 0 and 9 (in either order).
Therefore, for each pair of adjacent digits, of the 90 possible transposition errors, two will be undetectable. So the detection rate for transpositions is 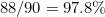 .
.
Noncommutative Schemes
The detection rates of the permutation scheme used for credit cards were pretty good, but another scheme, still using only one check digit in the range 0-9, can achieve a 100% detection rate for both single-digit errors and transpositions. On top of a permutation, it uses a so-called "noncommutative multiplication" operation on the digits of the code number.
Error Correction: two check digits
Being able to detect that an error has occurred is all well and good but it would be helpful to be able to correct it too. With more check digits, one can do just that.
Introducing a second check digit means that one can be used, as before, to detect and find the magnitude of an error, and the other can then locate and correct it.
As before, modulus 11 is an effective modulus. One good two-check-digit scheme uses modulus 11 twice but two different series of weights. Using these two check digits, all double errors can be detected and all single errors corrected.
We could go further and introduce even more check digits and thus be able to correct a greater number of errors. Of course, the downside is that the more check digits are used, the longer the number becomes - which is tiresome if the number is going to be typed in or copied down.
Conclusions
Error correcting schemes do not end here. They are used extensively with binary data and appear in our CD players, digital televisions and in the transmission of data from space probes. Some computer viruses even use error correcting codes to check and repair themselves it someone has modified them. A lot of these rely on polynomial arithmetic rather than check digits. One last class of error-correcting codes that do involve check digits are Hamming codes, which uses matrix manipulations to calculate check digits for binary data.
Error correcting also takes place in nature. It is believed that a lot of DNA which appears to be redundant is actually involved in an error correcting procedure which avoids errors in DNA replication, so it is fair to say that without efficient error detection and correction we would not be here.
About the author

I wrote this article whilst working with the Millennium Mathematics Project, during the summer of 2000, arranged and funded by the Nuffield Science Bursary Scheme.
Comments
Follow up, please!
Great article! I'd like to see a follow-up, ideally explaining (binary) Golay code and it's relation to group theory.