What is deep learning?
Deep learning is a particular type of machine learning. Machine learning algorithms are designed to solve specific tasks by learning directly from the experience of repeatedly doing the task themselves. These algorithms take inputs – data from the world that is fed into the algorithm – and give outputs – predictions of how to interpret what's going on.
Click here to see the entire artificial intelligence FAQ
Deep learning algorithms are some of the most effective modern algorithms. Rather than just transforming inputs into outputs, they transform the inputs into "fake inputs", which are then fed through a similar process, potentially lots of times, before the last collection of things you get are actually given as outputs. The “deep” in the name refers to this iterative procedure. Obviously what you get in the end is a just way of transforming inputs to outputs, but this deeply layered way of doing it turns out to work really well in lots of problems.
Since the 1980s neural networks have been used as the mathematical model for machine learning. Originally the neural networks consisted of just one or two layers but since the early 2000s deep learning algorithms have been designed using deep neural networks consisting of many layers. Deep learning is now used for tasks that vary from pre-screening job applications to revolutionary approaches in health care.
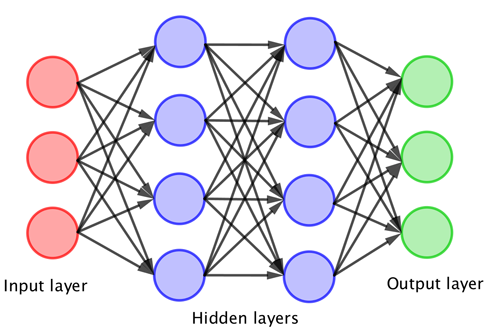
The typical architecture of a neural network – the more layers that you have the "deeper" network. The deep neural network transforms the original inputs into "fake inputs" that feed into the next layer, until it eventually produces the outputs.
This hierarchical structure of deep learning algorithms enables them to recognise structures in the raw input data and represent that data in very useful ways. For example, suppose the algorithm is designed to find pictures of a particular person in a large set of images. Then the raw input to the algorithm will be each of these images, expressed as the colour values of the pixels in the image. Then the first layer of the network is designed to identify features in the image, such as which pixels in the image are part of a face. Now the next layer of the network has the easier task of processing an image where shapes of faces have already been identified, rather than having to deal with the structureless mass of pixels in the original image. In this way the algorithm works itself towards the final answer (whether the specified person is in the image or not) layer by layer, extracting more and more features as it goes along.
You can read more in our introduction Maths in a minute: Deep learning.
About this article
This article was written by Kweku Abraham, Chris Budd, Marianne Freiberger, Yury Korolev and Rachel Thomas.
Kweku Abraham is a postdoctoral researcher in statistics at the University of Cambridge, working on the mathematics of deep learning.
Chris Budd is based at the University of Bath, where he is Professor of Applied Mathematics. He is also Professor of Maths at the Royal Institution and Gresham Professor of Geometry. He has also been the Education Officer of the London Mathematical Society, and Vice-President of the Institute of Mathematics and its Applications.
Yury Korolev is a Lecturer in Mathematics and Data Science and an EPSRC Postdoctoral Fellow at the Department of Mathematical Sciences at the University of Bath, and a Quondam Fellow of Hughes Hall, University of Cambridge.
Marianne Freiberger and Rachel Thomas are Editors of Plus.
This article was produced as part of our collaboration with the Mathematics for Deep Learning (Maths4DL) research programme. Maths4DL brings together researchers from the universities of Bath and Cambridge, and University College London and aims to combine theory, modelling, data and computation to unlock the next generation of deep learning. You can see more content produced with Maths4DL here.