The physics of language (continued): signature of a language
Over the previous two articles Sanjaye Ramgoolam, from Queen Mary, University of London, has explained how his experience as a theoretical physicist has motivated him to work on trying to understand language. As we saw in the first article, natural language processing (NLP) had produced vast datasets that represented words in a language as matrices and vectors. And Ramgoolam explained in the last article that studying the statistical distributions of matrices that arise in particle physics leads to new insights into experimental evidence. He saw the NLP data as a kind of evidence from the experiments analysing texts. "Language is a complex system, so maybe some ideas from complex systems in physics could work," he says.
Signature of a language
When we think of applying statistics, we often think of a population of people that come with various characteristics, such as height, weight, and age. In a similar way, as we saw in the first article, we can think of the words in a collection of texts as a population, with each word represented by a matrix. Each entry of the matrix can be thought of as a single characteristic of the corresponding word. If you construct the matrices using, say, 300 context words, then each matrix contains 300 x 300 = 90,000 entries, representing 90,000 characteristics for each word.
This means the NLP data is too complex to analyse all at once. To make things more tractable, Ramgoolam and his colleagues first analysed just one variable for each word – the top left entry in the matrix for each word: "We treat that variable as the one of interest, like the height variable for our population of people." With just one variable to think about per word, they could then build a histogram and analyse the data in the usual way.
Their work showed that there were two first order moments (the generalisations of the mean), and 11 second order moments (the generalisation of the standard deviation) for the NLP data. As we saw in the last article, this means that if the data is Gaussian, then all the higher moments can be calculated from these 13 numbers. These 13 numbers would function like a signature, characterising that particular language.
Testing if the NLP data was Gaussian meant solving the calculations so that you could express all the higher moments in terms of these first and second moments. Not surprisingly this was a profoundly difficult problem. In the end it was Ramgoolam's experience from physics that lead to the solution.
Solving with symmetry

Groups are a mathematical way of describing symmetry. This image is associated to the exceptional Lie group E8. It was generated on a computer by John Stembridge, based on a hand drawing by Peter McMullen.
The key lay in the symmetry of the data. You could have used a different order of context words when building your word matrices. This would result in the matrices for a particular word consisting of the same elements, but these elements reordered in a way that corresponds to the reordering of your context words. But the statistical distribution of this set of reordered word matrices should be unchanged – it is symmetric under the reordering of the context words.
Symmetry plays an incredibly important role in physics, and in particular in quantum physics (you can read more here.) For many years Ramgoolam has been working with the symmetries in quantum field theory, the mathematical description of quantum physics. "This is the kind of thing I've been working on for 30 years, using representations of symmetric groups. I usually work on that in the context of AdS/CFT in physics." (You can read about his work in that area here.) "I was able to use representation theory techniques to solve the 13 parameter model."
Once Ramgoolam had solved the mathematical expressions for the higher moments in terms of the 13 first and second moments (ie, solving the 13 parameter model), he and his colleagues could test the NLP data for Gaussianity. He got the best performing student from his Mathematical Techniques class, Lewis Sword, to work on it over the summer of 2019.
Ramgoolam and Sword theoretically predicted the value of the higher moments from Ramgoolam's mathematical results, and then tested these against the experimental data from NLP. They found that there was very good agreement between the predicted and experimental results for most of the higher moments, but there were some discrepancies too. "We're not postulating everything is exactly Gaussian, we're saying it's approximately Gaussian. The fact that it is broadly Gaussian is a success [for this approach]," says Ramgoolam.
The fact that the NLP data is almost Gaussian is very promising. In quantum physics, approximate Gaussianity allows physicists to make practical predictions about diverse areas of nature: from particle physics to cosmology. The hope is that approximate Gaussianity will be equally powerful in understanding languages.
Predictions from physics
Ramgoolam describes his approach to studying the NLP data as "very much a physicist's way of thinking about things." He had decades of experience using this approach in quantum field theory (QFT), the mathematical language that describes the fundamental particles and their interactions, called the standard model of particle physics. He used a lot of the ideas from QFT to technically develop linguistic matrix theory, the new approach for NLP. Coming from his experience working with matrices in QFT, he could see it as a generalisation of the statistics we all know. "You can think of statistics as a zero-dimensional QFT," he says. "The field you are dealing with, say the height of a person, is just 1 number."
And physics also provided the conceptual framework of taking a theory (a Gaussian description of the shape of the language), making predictions, and then comparing those predictions against the experimental data (the language data). "This is how QFT is applied in particle physics and cosmology." In particle physics the moments have predictive power: the quadratics in the standard model tell you what fundamental particle you are dealing with. And the higher moments allow you to make predictions about the interactions between these particles.
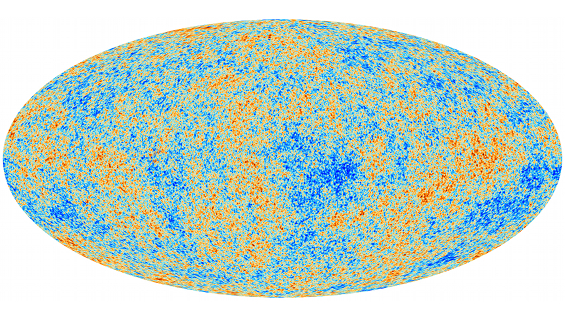
The all sky map of the temperature fluctuations in the CMB, as seen by the Planck satellite. (Image credit ESA and the Planck Collaboration)
In cosmology, physicists are investigating if the cosmic microwave background (the leftover radiation from the Big Bang) has Gaussian features. Understanding the distribution of this cosmological data would give us new insights into the nature of the early Universe. "The cosmic microwave background is approximately Gaussian – so we're looking for approximate Gaussianity in language. It's inspired, in a real genuine sense, by how QFT is applied in cosmology and particle physics."
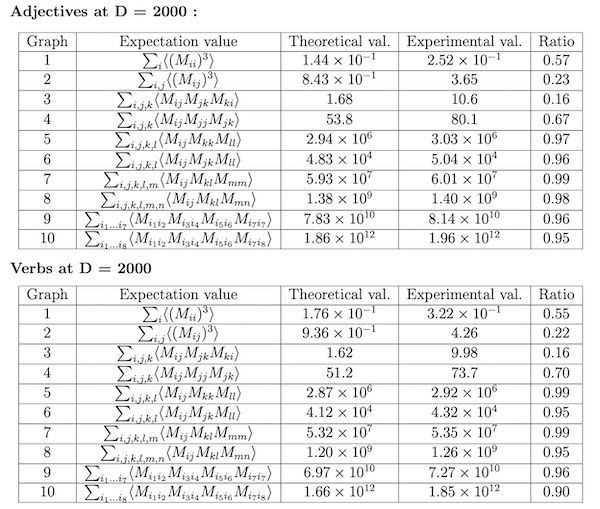
The predicted values and experimental values for the third and fourth order moments, for adjectives and verbs represented as 2000 x 2000 matrices. Where the ratios are close to one, the predictions closely match the experimental evidence. Note that the predictions closely match, and diverge from the experimental evidence, for the same moments for both the set of verbs and the set adjectives. (Table from Ramgoolam et. al. 2019)
In NLP, the language data seems to be approximately Gaussian, the first and second order moments do a good job of predicting most of the higher moments (where the ratio in the table is close to one) . "But the departures from Gaussianity are also interesting," says Ramgoolam. The experimental evidence for some of these higher moments differ from the predictions, they diverge from Gaussianity. And it might be these diverging higher moments that indicate some significant aspect of the language. These divergences from Gaussianity could be used to detect meaning from the randomness in a given language. They could also be included as part of the signature of a language, along with the thirteen parameters described above.
"When we started investigating whether approximate Gaussianity holds or not, we had no idea what to expect," says Ramgoolam. What is so exciting is that these potential signatures, both the 13 parameters of the first and second moments, and the non-Gaussianities where the experimental data departs from the predicted higher moments, don’t seem to depend on which parts of the NLP data you are looking at. The same results appear whether you are looking at the set of matrices for adjectives, the set of matrices for verbs, and so on.
"The Linguistic Matrix Theory programme arose from serendipitous interactions between scientists and lies at a fascinating interface of perspectives from theoretical physics, mathematics and computer science," says Ramgoolam. "I am very excited to be working, with a diverse group of collaborators, on the mathematical developments of the framework as well as the computational applications to natural language data. A few years ago I would not have imagined I would be working on the kind of collection of problems generated by Linguistic Matrix theory."
Sanjaye Ramgoolam explains how he is using techniques from physics to give new insight into language
About this article

Dr Sanjaye Ramgoolam is a theoretical physicist at Queen Mary University of London. He works on string theory and quantum field theory in diverse dimensions, with a focus on the combinatorics of quantum fields and the representation theory of groups and algebras. One of his recent research directions, sharing some of these mathematical mechanisms, is the development of an approach to the study of randomness and meaning in language.
Rachel Thomas is Editor of Plus.