
One of the most significant recent developments in artificial intelligence is machine learning. The idea is to look at intelligence, not as something that is taught to a machine (in the sense of a traditional computer program), but something that a machine learns by itself, so that it learns how to do complex tasks directly from experience (or data) of doing them.
In practice, a machine often learns by turning the parameters in a neural network – a big mathematical equation that is built from layers of smaller equations that are linked by these parameters. (You can find out more in our introduction to machine learning and neural networks.)
Supervised learning
Supervised learning is a bit like being taught at school when the teacher gives you a set of questions to try, and then they give you the answers to check your work against. The neural network is given a training set consisting of pairs of inputs and desired outputs (sometimes this is described as labelled data – the inputs are labelled with the so-called ground truth). A supervised learning algorithm aims to tune the parameters of the network to give output that matches the training set as closely as possible.
For example, suppose you want an algorithm to recognise the digits in hand-written numbers. Digital images of written digits first need to be mathematically translated into something a computer can understand. Techniques such as principal component analysis can automatically extract the main features in the image (perhaps how the image is spread out horizontally, or the number of straight line segments it contains) representing the digital image as a list of relatively few values.

Some sample images of hand-drawn numbers from the MNIST training set (Image Josef Steppan – CC BY-SA 4.0)
Starting with a massive set of images of written digits, such as the MNIST dataset, the learning algorithm will attempt to identify which images represent the same digit, and return an output of "0", "1", ..., "9". It will then compare its outputs to the correct labels from the training set using something like the mean square error. The network is then trained to minimise this error over all of the training set using something like the gradient descent algorithm. (You can read more detail about this approach in What is machine learning?)
Supervised learning produces very successful results, but the downside is it can be very time consuming and expensive, or even impossible, to put together a big enough training set of labelled data.
Semi-supervised learning
Recent advances have shown it is possible to get good results for certain tasks using a much smaller training set. In semi-supervised learning you only need to provide a very small set of hand-labelled training data, relative to the larger set of unlabelled data. Then the semi-supervised algorithm extracts as much structure as it can from the labelled and unlabelled data, and then uses this structure to propagate the labels across the whole data set.
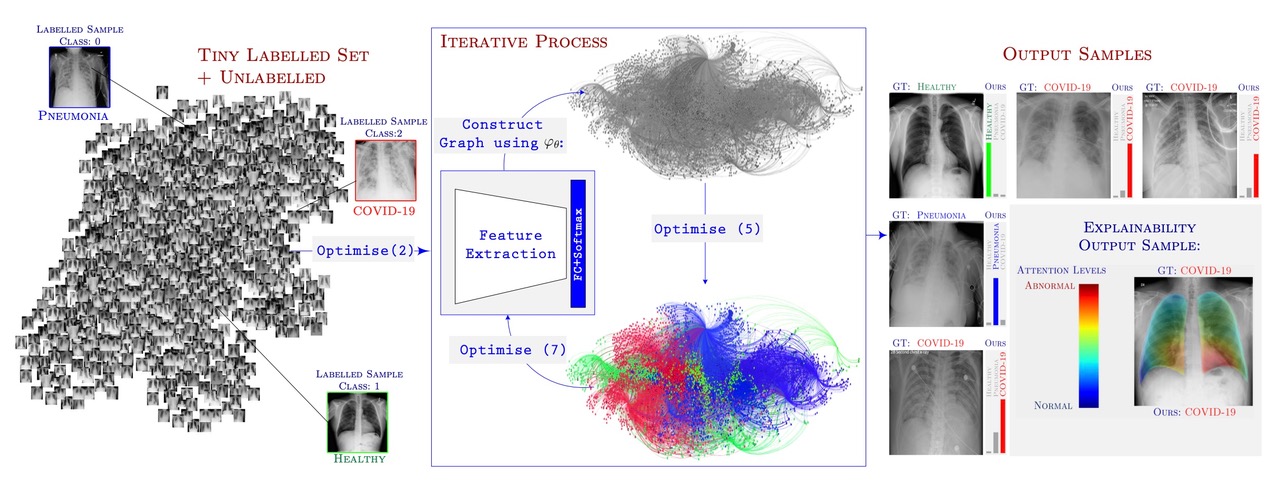
The workflow of the semi-supervised algorithm, GraphXCOVID, as detailed in the paper (Image used with permission of the authors)
A recent and very successful example of semi-supervised learning comes from identifying cases of COVID-19 from chest X-rays. The researchers hand-labelled only a tiny fraction in a large set of X-rays with the correct diagnosis of healthy, COVID or pneumonia from other causes. They then repeatedly looped through three steps.
Again the first step is to identify features that appear in the labelled and unlabelled X-rays this time using a combination of deep neural networks and mathematical techniques from image analysis (such as those in What the eye can't see).
Having extracted the features from the labelled and unlabelled images, the next step is to build a graph representing the set of X-rays. Each X-ray is a node in the graph and two X-rays are connected by an edge if they share similar features. In this way the graph captures the structures in the data set.
The final step takes the small set of labelled X-rays and uses a mathematical model of diffusion to propagate these labels to the unlabelled X-rays. You can imagine this as colouring each of the labelled X-rays with a colour representing their particular label (say, green for "health", blue for "pneumonia" and red for "COVID"), and these colours then diffusing through the connections in the graph to the unlabelled X-rays, like a drop of coloured dye would spread through a piece of paper.
The semi-supervised algorithm loops through these steps repeatedly, each step refining the next, until it reaches some optimal solution for labelling the whole data set. The algorithm can then go on to learn to distinguish X-rays that show signs of COVID from X-rays that don't by using this larger labelled data set. The researchers report their semi-supervised algorithm gives better results than the leading supervised algorithms, while only needing a fraction of the labelled training data.
About this article
This article is based on discussions with researchers from the INTEGRAL project, and on their research. You can read about some of their research in Seeing traffic through new eyes on Plus.
This article forms part of our coverage of a major research programme on deep learning held at the Isaac Newton Institute for Mathematical Sciences (INI) in Cambridge. The INI is an international research centre and our neighbour here on the University of Cambridge's maths campus. It attracts leading mathematical scientists from all over the world, and is open to all. Visit www.newton.ac.uk to find out more.