
What is machine learning?
This article is based on a talk in Chris Budd's ongoing Gresham College lecture series. You can see a video of the talk below and see other articles based on the talk here.
One of the most significant recent developments in artificial intelligence is machine learning. The idea is to look at intelligence, not as something that is taught to a machine (in the sense of a traditional computer program), but something that a machine learns by itself, so that it learns how to do complex tasks directly from experience (or data) of doing them.

Even relatively simple machine learning algorithms can learn how to tell a picture of a cat from a picture of a dog.
With the huge advances in computer speed, and developments in the algorithms used to program them, machine learning is growing very rapidly. The algorithms that result from it are starting to have a significant impact on our lives, and are often out performing humans. So how does machine learning work?
Learning from experience
In a machine learning system the computer writes its own code to perform a task, usually by being trained on a large data base of such tasks. A large part of this involves recognising patterns in these tasks, and then making decisions based on these patterns. To give a (somewhat scary) example, suppose that you are a company seeking to employ a new member of staff. You advertise the job, and 1000 people apply, each of them sending in a CV. This is too many for you to sift by hand so you want to train a machine to do it.
To make this possible you have on record all of the CVs of the many applicants to the company in the past. For each such CV you then have a record as to whether you actually employed that person or not. To train the machine you take half of the CVs and ask it to find out the patterns in them which correspond to whether that CV led to a successful employment application. Thus, if the machine is presented with a CV it can make a decision as to whether the person is employable. Having trained the machine you then test it on the other half of the CVs. Provided the success rate is sufficiently high, you then have confidence that it will be able to judge the employability of a person just from their CV. No human judgement need be involved at any stage. Such a procedure is entirely feasible with modern computer power, and it raises significant ethical questions, which I will return to in the next article.
The nuts and bolts
To make the process of machine learning more transparent, we will consider the question of pattern recognition using the very concrete example of developing a machine that can recognise hand-written digits. Such a machine should be able to accurately recognise which number a digit represents regardless of how it is written.

Handwriting can be hard to decipher even for humans.
The process of digit recognition has two stages. Firstly, we must be able to scan an image of hand written digits into the machine, and extract significant data from this (digital) image. This is usually done the statistical method of principle component analysis (PCA), which automatically extracts the main features of an image, for example its height, length, crossing points of lines in the image, and so on (you can find out more about PCA in the context of face recognition here). The procedure is closely related to that of finding the eigenvalues and eigenvectors of a matrix, and is also very similar to the procedure that Google uses to search for information in the world wide web.
Secondly, from these extracted features we want to train the machine to then recognise the digit. A very popular method to do this training is a neural net. This technique for machine learning is based very loosely on how we think the human brain works. First, a collection of software "neurons" are created and connected together. These are allowed to send messages to each other. Next, the network is asked to solve a large set of problems for which the outcome is already known. By doing this it "learns" how the connections between the neurons should be determined so that it can successfully identify which patterns in the data that lead to the correct outcome.
An early example of such a neural net is a single layer system called the perceptron which is meant to model a single neuron. The concept of the perceptron was introduced by Frank Rosenblatt in 1962. The typical architecture of a perceptron is illustrated below.
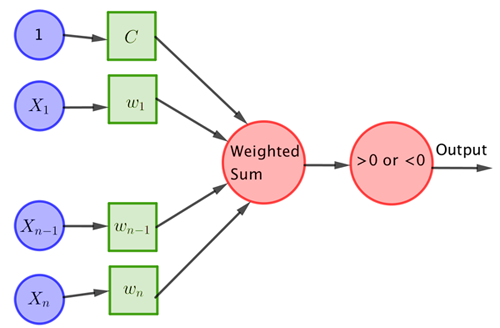
An example
As an example, imagine we extract only two features $X_1$ and $X_2$ from the image — $X_1$ might count the number of pieces of straight line in the image and $X_2$ the number of times lines in the image cross. Each image of a hand written 3 or 4 now comes with two numbers, and can thus be located on a coordinate system. Since a 3 generally has no straight line segments and no crossing lines, an image of a 3 is likely to correspond to a point that is close to the point $(0,0)$. With three straight line segments and one crossing point, images of a 4 are likely to be near the point $(3,1)$. Then the sum in the perceptron is given by $$w_1X_1+w_2X_2-C.$$ For given $w_1$, $w_2$ and $C$, setting this equation to 0 defines a straight line. If, using the training images, the perceptron manages to find values for $w_1$ and $w_2$ and $C$ so that the straight line separates all the points corresponding to the digit 3 and all the points corresponding to the digit 4, then it has a very good chance of identifying new images of digits correctly too. If such a straight line exists, then the data is called linearly separable.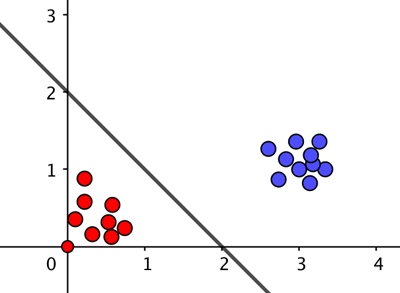
Suppose that the red dots come from images representing a 3 and the blue ones from images representing a 4. If the algorithm uses C=2, X1=X2=1, then the weighted sum set equal to 0 corresponds to the line shown. For the blue data points the weighted sum is greater than zero and for the red ones it is less than zero, so the algorithm will always give a correct answer for this data set.
If the data points cannot be separated by a straight line — if the data is not linearly separable — then you can spread the points out into a higher dimension and hope that they become linearly separable there. As a very simple example, you might draw points in the figure above "out of your screen" into the third dimension by a distance that corresponds to their original distance to the point $(0,0). Generally, though, more sophisticated approaches are used. And of course, if you are extracting more than two features from the original data, then you can use a similar approach in higher dimensions.
The perceptron approach also works with reasonable success for cats and dogs:
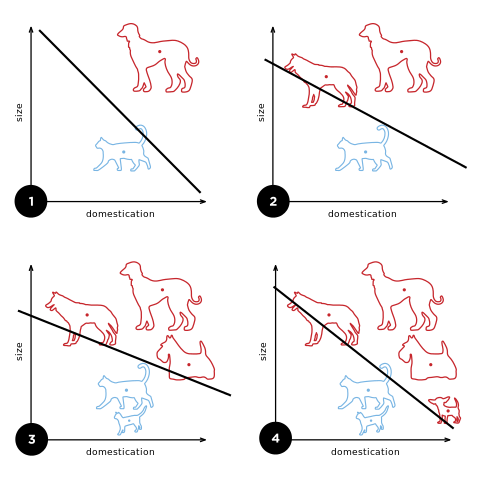
These figures demonstrate how the algorithm updates its choice of line (that is, the constant C and the weights w1 and w2) as more training data becomes available. Image: Elizabeth Goodspeed, CC BY-SA 4.0.
{kind=link}
Neural nets and deep learning
The simple perceptron could be trained to do many simple tasks, but quickly reached its limitations. It was obvious that more could be achieved by coupling many perceptrons together, but this development had to await the advent of more powerful computers. The big breakthrough came when layers of perceptrons were coupled together to produce a neural net. The typical architecture of such a neural net is illustrated below. In this case the inputs combine to trigger the first layer of perceptrons. The outputs from these combine to trigger the next layer, and finally these combine to give the output.
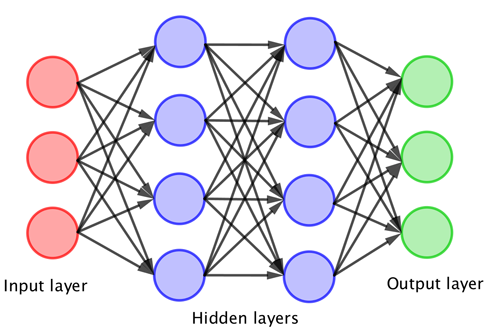
The more layers that you have the "deeper" network. Such a network is then trained by assigning weights to each of the connections above. This process is meant to resemble the way that the brain strengthens, or weakens, neural pathways. Deep learning describes the process of training such a neural network.
The fact that this is possible is due to the development of new mathematical optimisation algorithms, combined with extensive (in the case of Google's DeepMind vast) computer power. At the end of this process of finding suitable weights $w_i$ for the network you then have a black box which can run very quickly and which can make "decisions". You can play with setting up a neural net on this website.
Different approaches
As a quick aside it is worth looking at the process of learning in a little more detail. There are various forms of the learning process for a neural network.
In supervised learning a set of example pairs of inputs and outputs is provided in advance by the user of the network. The learning approach then aims to find a neural network that gives an output that matches the examples. The usual method of comparing the output from the neural net with that of the examples is to find the mean square error between the correct and actual output. The network is then trained to minimise this error over all of the training set. A very standard application of this is the use of curve fitting in statistics, but it works well for handwriting and other pattern recognition problems.
In reinforcement learning the data is not given in advance by the user, but is generated in time by the interactions of the machine controlled by the neural network with the environment. At each point in time the machine performs an action on the environment which generates an observation together with a cost of that action. The network is trained to select actions that minimise the overall cost. In many ways this process resembles the way that a human (especially a young child) learns.

To learn how to play chess the chess computer AlphaZero played 700,000 games against itself.
The mathematical algorithms for machine learning have advanced a great deal in recent years. Convolutional neural networks (CNNs) are an exciting, new, and important extension of these methods which combine image processing techniques with a deep neural net. They can be used for face recognition and even for detecting emotions. They are now being used in many other applications including medical diagnoses.
To learn how to play chess so well AlphaZero used a deep convolutional neural network. This was trained using a reinforcement method with the machine playing 700,000 games against itself over 24 hours. A general purpose Monte-Carlo tree search (MCTS) algorithm was used to allocate the weights. A similar approach was used to learn how to play Shogi and Go and in each case a similar level of performance was achieved. Impressive!
Progress in machine learning develops apace, with an ever increasing trend to have more sophisticated and deeper networks, driven by faster training algorithms and more and more data. But is it safe and ethical to leave potentially life-changing decisions, such as medical diagnoses, to machines? That's what we will look at in the next article.
About this article
This article is based on a talk in Budd's ongoing Gresham College lecture series (see video above). You can see other articles based on the talk here.

Chris Budd.
Chris Budd OBE is Professor of Applied Mathematics at the University of Bath, Vice President of the Institute of Mathematics and its Applications, Chair of Mathematics for the Royal Institution and an honorary fellow of the British Science Association. He is particularly interested in applying mathematics to the real world and promoting the public understanding of mathematics.
He has co-written the popular mathematics book Mathematics Galore!, published by Oxford University Press, with C. Sangwin, and features in the book 50 Visions of Mathematics ed. Sam Parc.
This article now forms part of our coverage of a major research programme on deep learning held at the Isaac Newton Institute for Mathematical Sciences (INI) in Cambridge. The INI is an international research centre and our neighbour here on the University of Cambridge's maths campus. It attracts leading mathematical scientists from all over the world, and is open to all. Visit www.newton.ac.uk to find out more.
Comments
vonjd
I just wrote a post on neural networks which should provide some more intuition on how they work: http://blog.ephorie.de/understanding-the-magic-of-neural-networks
Dr JV Stone
Thanks for a neat summary.
For readers interested in the history of deep learning, please see this blog:
A Very Short History of Artificial Neural Networks
Daily AI News
Your concise exploration of machine learning hits the mark for clarity and depth. Breaking down this complex topic into understandable components, you provide an excellent entry point for curious minds. The examples you offer, like recommendation systems and image recognition, showcase its real-world applications. This post serves as an essential primer for those new to the field, while also offering valuable insights for tech enthusiasts. By demystifying machine learning, you empower readers to appreciate its significance in modern technology. A well-crafted piece that educates and inspires further exploration. Well done!