
The mathematics of your next family reunion
– I am your father’s brother’s nephew’s cousin’s former roommate.
– What does that make us?
– Absolutely nothing!
(Lord Dark Helmet and Lone Starr, discussing family relationships in the Mel Brooks movie Spaceballs.)

Why is your great-grandmother great?
Keeping track of family relations can be difficult. If Edna marries your mother’s uncle Charlie, what should you call her? If your father’s cousin’s daughter just had a baby boy, how should you two be introduced? Who is your “great great aunt”, and how can you find your “first cousin twice removed”? Fortunately, a bit of mathematical logic can clarify who should be called what, and why – and even measure the degree of genetic similarity between different relatives.
Ancestor Lineage
To begin at the beginning (well, your beginning, anyway), you surely had two parents, a mother and father:
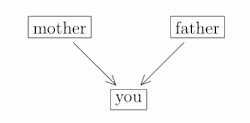
Continuing backwards, they each had two parents, giving you a total of four grandparents:
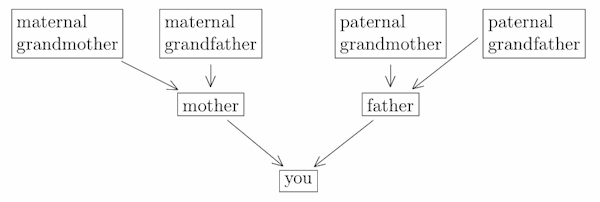
Going back still further, each of your ancestors in turn had two parents, indicated by prepending an extra “great” each time. For example, your maternal lineage is:
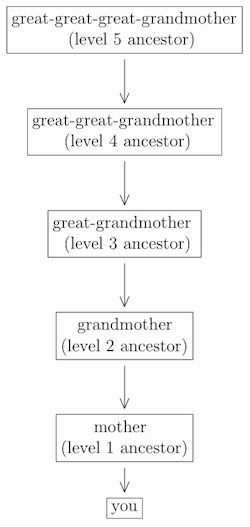
and so on (and similarly for “fathers” instead of “mothers” at any level).
Since each ancestor has two parents (one mother and one father), you have a total of 2n ancestors at level n: two parents, four grandparents, eight great-grandparents, sixteen great-great-grandparents, and so on. Summing up, you have a total of 2+22 +23 +...+2n =2n+1 − 2 ancestors of level n or lower; for example, your total number of parents and grandparents and great-grandparents combined is 23+1 − 2 = 16 − 2 = 14. In short, your ancestors form a perfect binary tree – simplicity itself.
Descendant legacy
If you have children yourself, then their children are your grandchildren, and your grand-children’s children are your great-grandchildren, and so on:
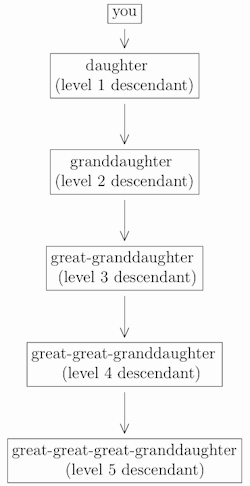
(and similarly for “son” instead of “daughter” at any level).
Unlike with ancestors, there is no simple formula for your number of descendants. Rather, you have to count up all of your children, and all of their children, and so on. For example, even if you have five children, it is possible that none of them will have children of their own, in which case your number of grandchildren will be zero. On the other hand, if they each have five children of their own, then you will have twenty-five grandchildren – a lot more.
Sideways, march!
When people have more than one child, this fattens the family tree, creating new relationships like sister and niece and great-aunt and more. For starters, if your parents have additional children besides you, then they are of course your siblings, that is your sisters and brothers:
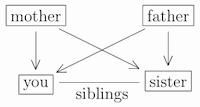
(Here, and throughout, relationships to “you” are written within the boxes, and relationships between other pairs of individuals are indicated by connecting lines.)
If you and your siblings each have children, then those children are first-cousins of each other. Then, if the two first-cousins each have children, then those children are second-cousins of each other; and their children are third-cousins, and so on:
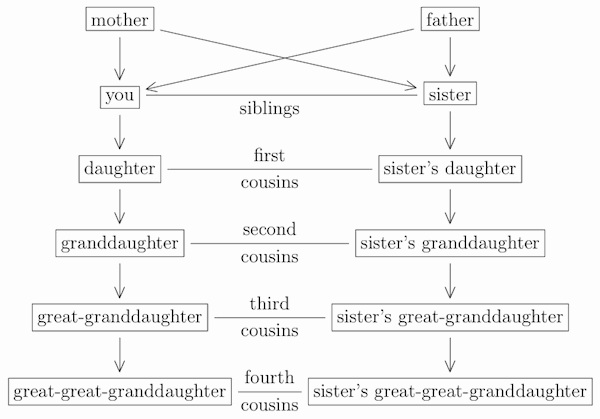
(and similarly for “son” instead of “daughter” at any level).
In general, n-level cousins share two (n + 1)-level ancestors (but no n-level ancestors). Thus, first-cousins share two grandparents (but no parents), and second-cousins share two great-grandparents (but no grandparents), and so on.
It follows that if A and B are n-level cousins, then A’s child and B’s child are (n+1)-level cousins. Thus, children of first-cousins are second-cousins, and children of second-cousins are third-cousins, and so on. In fact, if we regard siblings as 0-level cousins, then this reasoning applies to siblings too: children of 0-level cousins (ie, siblings) are themselves first-cousins.
Finally, your sibling’s child is your niece (or nephew, if male), and their child is your great-niece (or great-nephew), and so on:
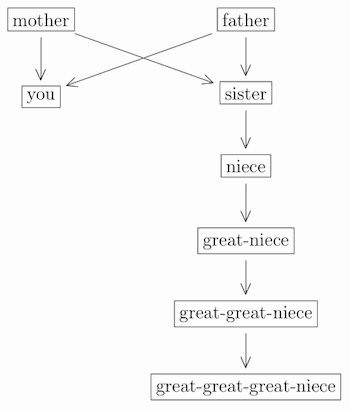
(and similarly for “nephew” instead of “niece” at any level).
Cry Uncle
So now we know where your descendants’ cousins come from. To see where your cousins come from, we have to move up to your parents’ level. Your parents’ siblings are your aunts and uncles, and their children are your first-cousins (since you and they share the same grandparents, but not the same parents):
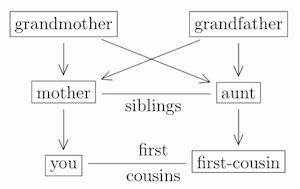
If your cousins have children, then what are they to you? Well, children of your first-cousin are called your “first-cousins-once-removed”, and their children are your “first-cousins-twice-removed”, and so on:
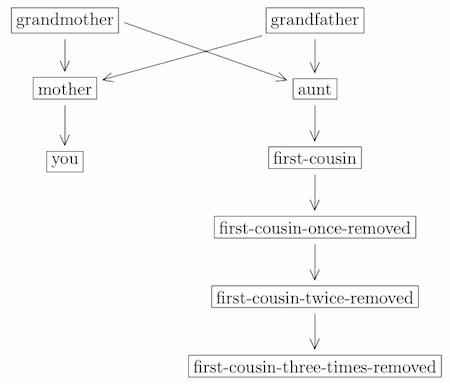
To see where your second-cousins come from, we have to move one more level up. Your grandparents’ siblings are your great-aunts and great-uncles. So their children (ie, your parents’ cousins) are your first-cousins-once-removed. And their children are your second-cousins:
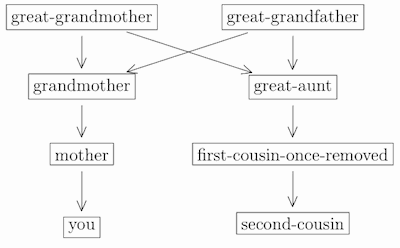
The same pattern continues upwards for all earlier generations. Once again, your nth cousins share your (n + 1)-level ancestors, but not your nth-level ancestors. Siblings of your nth-level ancestors are your great-...-great aunts and great-...-great uncles, where “great” is repeated n − 1 times. Furthermore, the nth cousins of your mth-level ancestors, and also the mth-level descendants of your nth cousins, are your nth cousins m times removed.
For example, with n = 3 and m = 2, this says that your grandparents’ third-cousins are your third-cousins-twice-removed, and your third-cousins’ grandchildren are also your third-cousins-twice-removed. Tracing back to n = 3 gives:
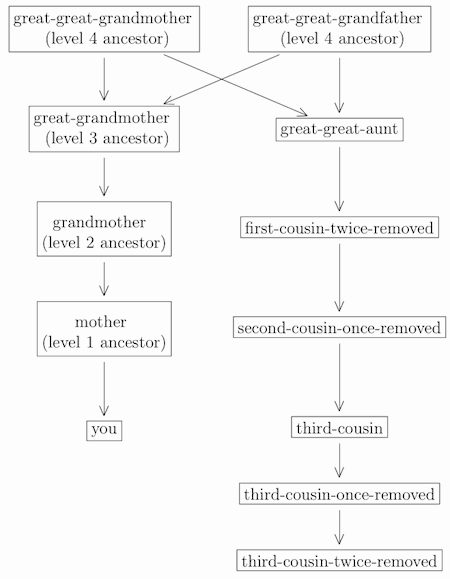
In this diagram, your third-cousin (n = 3) shares two of your great-great-grandparents (level n + 1 = 4 ancestors) but none of your great-grandparents (level n = 3 ancestors). Your great-great-aunt is a sibling of your great-grandmother (n = 3). Your second-cousin-once-removed achieved that designation by being the second cousin (n = 2) of your mother (level m = 1 ancestor), while your third-cousin-once-removed achieved that designation by being the daughter (level m = 1 descendant) of your third cousin (n = 3). Tricky!
Thicker than water
One of the reasons we care about family trees is because of a sense that certain family relations are “more related” to us, and should be assisted and protected and loved on that basis. This attitude presumably has an evolutionary basis: our genes survived through the ages because our ancestors made efforts to help them survive by caring not only for themselves, but for their close relatives too. Indeed, there is an ancient Bedouin Arab saying, “I against my brother, my brothers and me against my cousins, then my cousins and I against strangers”, which nicely illustrates the philosophy of caring most for those who are genetically closest to us.
This raises the question of just how similar our relatives’ genes are to our own. Well, first of all, about 99.9% of our genetic material is common to all humans (yes, even your in-laws), and indeed is what makes us human. Furthermore, some people may share other genes with us just by chance; for example, if I meet a stranger whose eyes are brown just like mine are, that does not necessarily establish that we are close relatives. In addition, there is lots of randomness in how genes are passed on (each individual gets half of their genetic material from their mother and half from their father, but which bits come from which parent is chosen at random and cannot be predicted), so we cannot draw precise conclusions with certainty.
To deal with all of this, we assign to each pair of individuals a relatedness coefficient which represents the expected fraction (ie, the fraction on average) of their genes which are forced to be identical by virtue of their family relationship. This approach averages out all of the randomness, while focusing on genetic similarities specifically due to family connections.
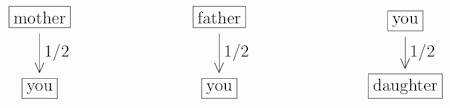
According to this definition, strangers have a relatedness of zero (the smallest possible value). By contrast, your relatedness with yourself is one (the largest possible value). Other relatedness coefficients fall between these two extremes. For example, your relatedness with your mother is 1/2, since you obtain half of your genetic material from her. And your relatedness with your father is also 1/2. By the same reasoning, your relatedness with your child is again 1/2. So far so good:
Next consider your maternal grandmother. She gave half of her genes to your mother, and then your mother gave half of her genes to you. It is possible that the half you took is exactly the same as the half your grandmother gave. It is also possible that the half you took has no overlap at all with the half your grandmother gave. But on average, that is, in expectation, exactly half of the genetic material you took from your mother originated from your maternal grandmother. So, your relatedness coefficient with your grandmother is one-half of one-half, that is, (1/2) × (1/2), or 1/4:
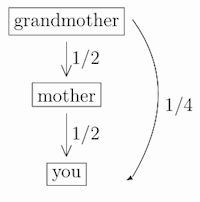
Continuing up the tree, your relatedness with your great-grandmother is one-half of one-half of one-half, that is: (1/2) × (1/2) × (1/2), or 1/8:
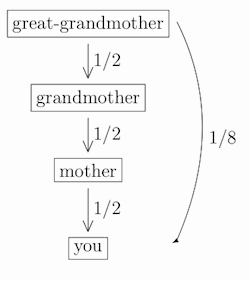
(and similarly for “father” instead of “mother” at any level). In general, your relatedness coefficient with your level-n ancestor is 1/2n.
By the same reasoning, your relatedness coefficient with your level-n descendant is also 1/2n. So, for example, your relatedness coefficient with your daughter is 1/2; with your granddaughter is 1/4; and with your great-granddaughter is 1/8 (and similarly for “son” instead of “daughter”).
For siblings, the situation is a little bit more complex. Consider first the case of two half-siblings (half-sisters or half-brothers), that is, people who share just one parent. Since they each got half of their genetic material from that one shared parent, their relatedness coefficient is one-half of one-half, that is 1/4:
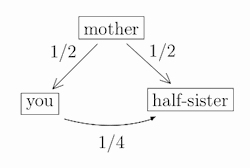
Regular (full) siblings similarly share 1/4 of their genetic material through their mother, but also share 1/4 of their genetic material through their father. This gives a total relatedness coefficient of 1/4 + 1/4 = 1/2:
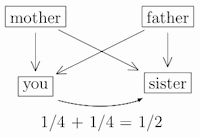
(One special case is identical twins, who have identical genes and thus a relatedness coefficient of one. But fraternal twins have relatedness coefficient 1/2, just like other siblings.)
Continuing onward, since your mother and aunt are siblings, they have relatedness coefficient 1/2. Meanwhile, you and your mother have relatedness coefficient 1/2. Putting this together, you and your aunt (or uncle) have relatedness coefficient (1/2) × (1/2) = 1/4:
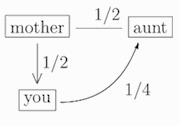
(and similarly with “aunt” replaced by “uncle”). And, your relatedness coefficient with your niece or nephew is also 1/4.
Then, since your first-cousin has relatedness coefficient 1/2 with your aunt, who in turn has relatedness coefficient 1/4 with you, it follows that you and your first-cousin share relatedness coefficient 1/8:
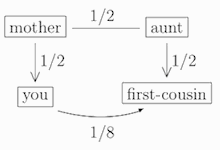
Now, since your mother and her first-cousin have relatedness coefficient 1/8, and since you have relatedness coefficient 1/2 with your mother, and since your mother’s first-cousin has relatedness coefficient 1/2 with her own child (who is your second-cousin), it follows that your relatedness coefficient with your second-cousin is (1/2) × (1/8) × (1/2) = 1/32:
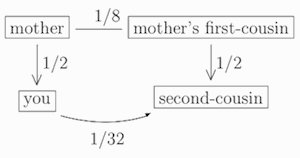
In general, switching to level-n cousins from level-(n − 1) cousins introduces two new factors of 1/2. Since (1/2) × (1/2) = 1/4, this means that your relatedness coefficient with your level-n cousin is always 1/4 times your relatedness coefficient with your level-(n − 1) cousin. It follows that your relatedness coefficient with your level-n cousin is equal to 1/22n+1.
So, your relatedness coefficient with your first cousin is 1/8; with your second cousin is 1/32; with your third cousin is 1/128; and so on.
What about first-cousins-once-removed, and all of that? Well, since you and your first- cousin have relatedness 1/8, and since your first-cousin and their child (your first-cousin- once-removed) have relatedness 1/2, it follows that you and your first-cousin-once-removed have relatedness coefficient (1/8) × (1/2) = 1/16:
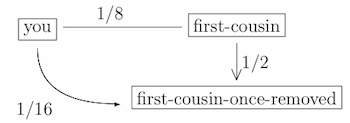
The pattern continues, with each new “removed” introducing an extra factor of 1/2 into the product. It follows that your relatedness coefficient with your nth cousin, m times removed, is equal to 1/22n+m+1. For example, your relatedness coefficient with your third cousin (n = 3) twice removed (m = 2) is equal to 1/26+2+1 = 1/29 = 1/512 – not very close at all.
We can summarise the relatedness coefficients of various relationships in a table:
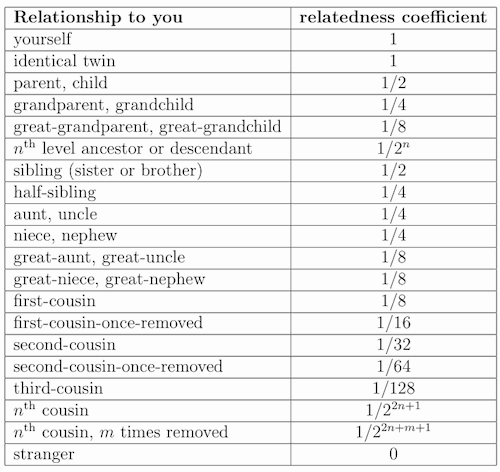
This table can be thought of as indicating your level of evolutionary imperative to protect and assist your various relatives. That perspective was nicely summarised by the early evolutionary biologist J.B.S. Haldane, when he was asked if he would give his life to save a drowning brother, and replied “No, but I would to save two brothers or eight cousins.” He was merely observing that 2 × (1/2) = 8 × (1/8) = 1, i.e. that two brothers, or eight cousins, are each “equal” (in evolutionary terms) to one copy of yourself.
So what about that saying, “I against my brother, my brothers and me against my cousins, then my cousins and I against strangers”? Well, in the context of relatedness coefficients, it corresponds to the observation that your relatedness coefficient is higher with yourself (1) than with your brother (1/2), higher with your brother (1/2) than with your first-cousin (1/8), and higher with your first-cousin (1/8) than with a stranger (0). That is:
1 > 1/2 > 1/8 > 0.

Different life forms can lead to different mathematics: eg, in many species of bees and ants the males have only half as much genetic information as females. You can read more about the intricacies of bee relationships in the appendix!
It seems that those Bedouins knew their inequalities well!
Families of all shapes and sizes
Of course, the evolutionary imperative associated with relatedness coefficients does not tell the whole story. You would (hopefully) protect your spouse over your second-cousin even though, strictly speaking, your relatedness coefficient with your spouse is zero (since you have no actual blood relationship). And, parents of adopted children should surely treat them just like biological children, despite the lack of true genetic connection.

Other family relationships can arise too. For example, if you marry, then your spouse’s relations become your corresponding in-law relations – your husband’s father is your father- in-law, your husband’s cousin is your cousin-in-law, and so on. The suffix “in-law” is also used for those who marry your relations – for example, your brother’s wife is your sister-in- law. (One exception is that your aunt’s husband gets to be called your uncle, even though he is “really” your uncle-in-law; and similarly your uncle’s wife gets to be called your aunt.)
Meanwhile, a woman who marries your father after your mother becomes your step-mother (or step-father, if the genders are reversed). Her relations become your corresponding step-relations – your father’s second wife’s brother is your step-uncle, and his children are your step-cousins, and so on. Of course, your genetic relatedness coefficient with your in-laws and your step-relations is zero, since your relationship is through marriage rather than actual blood lines.
Family relations can lead to unexpected surprises. At a recent large family reunion, I met a young man whom I did not know. After some discussion, we determined that my great-grandfather was the brother of his great-grandmother – making us third cousins. Furthermore, my great-grandmother was the sister of his great-grandfather, too. That is, three generations earlier, a brother-and-sister pair had married off with a sister-and-brother pair. This meant that he and I were third-cousins by each of two different paths – we were “double third-cousins”! It followed that our relatedness coefficient was twice that of usual third-cousins – that is, equal to 2 × (1/128) = 1/64 – still not very close, but interesting nonetheless. I wish I had had the presence of mind to immediately say to him, “Pleased to meet you, double-third-cousin. I am honoured to share one sixty-fourth of your genes.”
About the author

Jeffrey S. Rosenthal is a professor in the Department of Statistics at the University of Toronto, and the author of the popular book Struck by Lightning: The Curious World of Probabilities.
Comments
Anonymous
This article is very ethnocentric: going back to Toronto it might help, but not so much if you're headed to your ancestral village.
If your ancestors really formed a perfect binary tree, you would have billions of ancestors at a time when humans existed at most in the millions, so all humans have multiple paths of descent. In a village with constant population of a few hundred, the cross branches have to be within living memory. They don't partition neatly into generations, either.
In such places genetic your relatedness coefficient with your in-laws and your step-relations is far from zero, since your relationship is through marriage and actual blood lines. In an Indian village, your father's father's father's third wife might be your mother's sister or aunt, and their children share genes with you along both pathways -- and the language is rich with vocabulary to describe such possibilities. A friend in Bangalore told me a hobby of her mother's was to list all the possible ways to describe her kinship with her own husband.
My Kannada teacher told me about a group of women learning English, trying to figure out how to refer to your mother's older sister and your mother's younger sister: these are such different relationships to you that the single word 'aunt' could not possibly cover them both. Seniority matters as much as gene overlap! They finally decided that the words must be "maxi-mum" and "mini-mum".
Anonymous
Thank you for the step-by-step explanation of relationships and how to calculate the coefficient of relatedness. It was very helpful!
Anonymous
Marianne
Thanks very much for letting us know, we're looking into it.
Anonymous
I stopped here after reading an article that 20% of marriages in the world are between 1st cousins and another high percentage in some cultures are uncle-niece marriages so it would be nice to see an analysis of these trees and genetic contribution given any known level with this marriage type.
Anonymous
Hey, My Dad has remarried and he and his wife (my step mum) are planning kids. Obviously that makes them my half-siblings. I tracked the family tree down another generation but what I'm really curious about is what my grand-kids would be to my half-siblings kids?
Anonymous
1. You will be the half-sibling of your half-sibling.
2. You will be the half-aunt or half-uncle of your half-sibling's children, and they will be your half-neices or half-nephews.
3. Your children will be the half-neices or half-nephews of your half-sibling, and your half-sibling will be their half-aunt or half-uncle.
4. Your children will be the half-first cousins of your half-sibling's children, and vice versa.
5. Your grandchildren will be the half-great-neices or half-great-nephews of your half-sibling, and your half-sibling will be their half-great-aunt or half-great-uncle.
6. Your grandchildren will be the half-first cousins once removed of your half-sibling's children, and vice versa.
7. Your half-sibling's grandchildren will be your half-great neices or half-great nephews, and you will be their half-great aunt or half-great uncle.
8. Your half-sibling's grandchildren will be the half-first cousins once removed of your children, and vice versa.
9. Your half-sibling's grandchildren will be the half-second cousins of your grandchildren, and vice versa.
Anonymous
My great grandmother had six kids with my great grandfather. He passed away and a few years later she married his youngest brother and they had three children. What would be the proper term used to describe the different relationships here. Would you be cousins or half brothers/sisters in the different set of kids. Would your mothers new husband still be your uncle or your step dad? Would you share more DNA with your half brothers/sisters since the fathers were brothers? If so can you calculate this for me?
anonymous
They are 3/4 siblings. Not a term used much in humans but quite common in pedigree livestock (eg racehorses).
Anonymous
They would be half cousins I think
Anonymous
Very interesting - I've been working on a family tree, and though it is only 8 generations at its deepest, is wide and contains over 1,800 people, and I am now working on filling in these annoying voids, or attempting to link family fragments to mine who say they are related but I can't find the link, and make any corrections, etc.
Add to this journey my recent DNA testing, which has brought some 369 people potentially into my family. However, the most related someone is to me is 0.68% (and as yet they are "anonymous"). The only person of that list who I KNOW is already in my tree is related to me because our great-grandmothers were sisters, or we share a great-great grandfather. (Actually, we share a great-great grandfather AND his wife, our great-great grandmother, so how does that not double the amount of shared genes?) And yet, according to the test, we share only 0.13% genes, which I assume is rounded up from 0.125%, but who knows. Is it possible to share so little when, according to your math, if we are 3rd cousins, then we should share over 4 times as many genes? When it hit me that this is ACTUAL shared genes rather than AVERAGE ASSUMED shared genes. I guess we ACTUALLY share less than 50% in each generation of cousins. How else to explain this, unless the test is wrong? Similarly, there are people more related than this in the test, for example one who shares 0.50%, so we should at LEAST be third cousins, right? - and yet we cannot find a single family surname that is familiar going back as far as we traced. What is going on here?
Another thought - with the rise of DNA testing and law, I wonder if ACTUAL shared genes will be a determining factor in certain cases. Under the law someone could have a dozen great-grandchildren, but they won't all have the same percentage of DNA from their shared great-grandfather. Used to be things would be willed "to the oldest" but might things in the future be willed "to the descendent who shares the greatest ACTUAL percentage of my DNA?"
PETER NEWCOMB
With parents, I am guaranteed to get 1/2 of your genes from one, and 1/2 of my genes from the other. My children are guaranteed to get 1/2 of my genes and 1/2 of their mother's genes. But when I pass half of my genes down, it is not guaranteed that half will be my father's and half will be my mother's. I could pass 3/4 of my father's and 1/4 of my mother's. And my next child might get 1/4 of my father's and 3/4 of my mother's. On top of that, my children may (read WILL) not get the same genes passed from my father and mother. Those two children may not have ANY genes in common with each other. If they both tested DNA, both would match 50% with me, but compared to each other could conceivably test 0%. Statistically, that is improbable, but the further down the tree you move, when the statistical percentages become much lower, then the actual percentages could deviate significantly.
Now in your example of the person who SHOULD be a third cousin because of how much you share but you cannot find a shared family surname, you must remember that actual parentage and assumed parentage in three or four generations of all children may not always be the same. (This is referred to as a "non-paternity event" clinically or sometimes "cheating" socially).
This article https://isogg.org/wiki/Non-paternity_event#Historical_NPE_statistics has some interesting statistics on NPEs.
Anonymous
Loved the article.
I've long wondered about the math behind my buddy's nieces and nephews' genetic relatedness.
His brother and sister are married to another set of sister and brother. The younger pair met at the olders' engagement party. Aww.
So ten years into the marriages there are six kids - three from each couple. What is the relatedness between these sets of cousins? Is it 1/8 rather than the 1/16 we normally see in first cousins? All of the kids have a similar appearance, but the biggest resemblance is between two of the cousins rather than any of the siblings.
Anonymous
I have been wondering that myself. My biological father has 3 female double first cousins so what would I be to my fathers double first cousins children? If double first cousins are considered to be 1/2 siblings then they would make them pretty much my aunts so would their children and myself be more like first cousins?
Anonymous
My sister is dating a guy who's mom married our first cousin. The guy has a different father. So what would you call the relation?
Anonymous
Actually, nothing! A stranger to you by relation.
Anonymous
My paternal grandfather's brother is my cousin's great grandfather. In this same example, one set of my great-grandparents are my cousin's great-great grandparents. Are we third cousins 1x removed?
Anonymous
What would I be to my aunt's husband's grandchildren?
Anonymous
If your aunt's husband's grandchildren are not also your aunt's grandchildren, then you are not genetically related to his grandchildren -- the link is through marriage only, not sex.
Anonymous
This is all wrong: the parents start out with only 2 million base pairs of their genome ( 3 billion base pairs) different from each other. Although 1/2 your genes come from each parent 99.933 % of those genes are identical 2 x 10^6 / 3 x 10^9 = .00067 = .067%. That's why we all, save a very few, have 2 arms, 2 legs, 7 cervical vertebrae, etc. are are defined as a species. If parents had only 1/2 their genes in common they would be life forms at all, or at least one of them wouldn't.
Anonymous
My great grandmother had my grandma. Then had another daughter to another man.
What does that make my second cousin on that side? What is our relatedness?
Anonymous
My maternal great grandmother and my paternal great grandmother was the same person. In her first marriage she had my grandmother who was my mothers mother and then in her second marriage she had my fathers father. So what kind of cousins were my parents who had the same grandmother but different grandfathers.
Anonymous
If a persons great great great grandparent (5th level ancestor) is another persons great great grandparent (4th level ancestor). Are they either 4th or 5th cousins once removed?
Anonymous
My husband may have a granddaughter from a previous relationship. We have to sons. How are our children and his granddaughter related?
Anonymous
Simply put your sons would be her uncles through your husband's blood not yours.
Anonymous
Who is closer to my great grandson? Me his maternal great grandmother or his paternal aunt.
Anonymous
Great grandmother
Anonymous
If I know Person A and they are my Aunt through marriages niece what are they to me? If thay doesn't make sense, Person A has an aunt who is also my aunt through marriage so what is Person A to me? Thanks
Anonymous
Fascinating! So if I have a child and a subsequent grandchild, and my brother has a grandchild, what are the grandchildren to each other? I can't figure it out?!
Anonymous
Second cousins?
Anonymous
My father's brother married my mother's sister; what is the genetic relationship between me and my uncle and aunt's daughter, compared with the children of the sister of my father and uncle? She and I (but not my brother or her sister) and one of her sons share, what some people regard as strange, the ability to detach ourselves, where it it seems to us obviously rational and advantageous to ourselves or others, from the 'normal' emotional reaction to 'bad' events.
I'd also like to remark that clicking on your 'Mollom' link has amazed me that 'statistical computations' can reveal what seem to me (and no doubt countless others) as seemingly abstract ideas of quality. I shall see if the contents of your book are within my grasp.
Anonymous
You seem to describe the ability to allocate emotion that is both necessary and appropriate to a given situation, while simultaneously remaining clear headed. I have found this trait almost exclusively exists among those whose "mindset" falls within the HFA region of the Autism Spectrum Scale. Ever wonder why you see complicated problems so clearly when others are confused?
kate
I have met two people who are married to each other and their fathers are brothers,what does that make them.
Anonymous
First cousins, because the daughter would be the niece to her father's brother, and he would be her uncle.
Riley Hernandez
What if your cousin dated someone they had a baby, then they broke up. Later on the "someone" married and had kids. Would we be related?
Marty
Assume my father's direct 2nd grand parents were actually brother and sister, and my father and grandparents are deceased, is there a clue in my DNA that my 3rd great grand parents were brother & sister?
LarsB
I have taken a DNA test, and found out I shared over a percentage of DNA with a person. Through church records I found out that we are 5th cousins, - but doubly in the last generation, i.e., we have two sets of shared 4xgreat grandparents. If we had only one set, our shared DNA should have, on average, been 0.04% which is 25 times less.
I am sure that other factors (kinship I don't know, measurement errors at the website, the fact that the amount of DNA passed down in each generation obviously differs (law of great numbers), etc), matter, but it makes me curious about what the theoretical average shared DNA between us would be. You can't simply double the kinship for 5th cousins, can you? You need to do something fancier, methinks.
Crystal
Boy #1's mother's cousin's grandfather's brother is the grandfather of boy #2's mother; how are boy #1 and boy #2 related?
Austin
So my aunt is getting married in 9 days and we want to know this:
My mom is my mom and she has a brother or aka my uncle.
My uncle is marrying a woman who WILL be my aunt but....:
WHAT IS MY SOON TO BE AUNT'S SISTER TO ME? apparently it's nothing. Pleases help ASAP
Ken
My grandfather had 18 kids and his brother had 12 for 30 total. About how many cousins would I have ?
Tom
"The same pattern continues upwards for all earlier generations. Once again, your nth cousins share your (n + 1)-level ancestors, but not your nth-level ancestors. Siblings of your nth-level ancestors are your great-...-great aunts and great-...-great uncles, where “great” is repeated n − 1 times. Furthermore, the nth cousins of your mth-level ancestors, and also the mth-level descendants of your nth cousins, are your nth cousins m times removed." What are the logical limitations of m and n to each other? M and N = zero are self? M =1 is parent or child, thus N cannot be a first cousin, thus N cannot = 1, if M = 1. N >= M-1? That would make you your 0th cousin: Lets say that N >=1, and M>=1, for common use. Now what logical relations can N and M have to each other? Just N>=M-1?
Savannah Brooks
If I am my maternal grandfather's granddaughter and I am about to be married, what is my fiance to my grandfather
Arlene
My husband, person #1 had a grandmother, Bessie. Person #2 had a great-grand-mother whose sister was Bessie. What is the relationship between person #1 and person #2? Third cousins once removed??
Anonymous
No. They're second cousins, once removed.
Ryan
Very ineresting, i thought the removed was only when a devorce occured. Einstein would be quite impressed with your mathematics. So does this mean we are all in some way eachother’s cousin?
If I got married to someones daughter and then that someone got married to my uncle what would the structure be?
Confused.com
Interesting article, thanks.
I wonder if anyone can give me a perspective on the relationship between my children and my brother's wife's descendants from a previous marriage?
My brother's wife was previously married, from which she has a son & daughter, and 2 x grandkids via the daughter. My brother, I guess is the step-dad of her grown up children, and the step-grandad of the grandkids - would that be correct?
Are his step-kids and step-grandkids any relation to me? Are they my niece & nephews in law, and great niece & nephew in law?
What relation are those people to my children? I guess the grown up kids are my kids cousins in law? What does that make the grandkids (closer in age to my own kids actually)?
I'm confused.
Thanks.
Anonymous
What is my first cousin’s half sister to me?
Patti
I think it depends on how your first cousin and her half sister are connected. In other words, let's assume that your first cousin and her half sister share a mother but have different fathers. Their mother is the sister of your mother. This makes both the first cousin and her half sister your half cousin. Now let's assume that your first cousin and her half sister share a father, but have different mothers. Your first cousin is your cousin because her mother is your mothers sister. But her half sister has a different mother. The half sisters are related because they share a paternal father. Their father is not related to you by blood, he is the first husband of your aunt, technically your uncle or ex uncle by marriage.
sis not related to by blood. Her mother is actually someone
Patti M
It depends on the connection between the half sisters. Let us assume that your mother and sister have children. You and your aunties children are first cousins. Your aunt and uncle split up. Your uncle has another child with his new wife. That child is the half sibling of your cousin because they share a father but the half sibling is not technically related to you. Then your aunt marries again and has another child. That child is your cousin, and is the half sister of your cousin.
William C. McKinney
My Mother was adopted by my Fathers Uncle and Aunt (no blood relation) They had 3 sons and a daughter together. What relationship is my mother to them (bloodline) and what relationship would I have to them and the sons and daughter and their descendants?