Plus Advent Calendar Door #20: Deep learning
We no longer think twice about speaking to our digital devices, clicking on recommended products from online stores, or using language translation apps and websites. Many aspects of our lives today are possible thanks to machine learning – where a machine is trained to do a specific, yet complex, job.
Machine learning is one of the most significant recent developments in artificial intelligence. The idea is to look at intelligence, not as something that is taught to a machine (in the sense of a traditional computer program), but something that a machine learns by itself, so that it learns how to do complex tasks directly from experience (or data) of doing them. Advances in engineering and computer science are key to progress in this area. But the real nuts and bolts of machine learning is done with mathematics. A machine learning algorithm boils down to constructing a mathematical function that takes a certain type of input and reliably gives the desired output.

Machine learning algorithms can learn how to tell a picture of a cat from a picture of a dog.
There are various approaches to machine learning but the most common method is using something called a neural network. This is really a way to structure a complicated mathematical function. Artificial neurons, which themselves are a mathematical function, are arranged in a series of layers, taking a sort of sum of the outputs of the neurons in previous layers as an input. Then a neuron applies a complex mathematical function to that input and then passes the output of this on to the neurons in the next layer.
The network is then trained by working through lots of training data, and applying a machine learning algorithm that tweaks the parameters in the sums that link one layer to the next. With enough training data the parameters are tuned until the neural network has settled on a complicated mathematical function that carries out its given task, such as correctly distinguishing between cats and dogs. (You can read more about the nuts and bolts of this process in our gentle introduction: Maths in a minute: Machine learning and neural networks.)
Going deep
Since the 1980s neural networks have been used as the mathematical model for machine learning. Originally the neural networks consisted of just one or two layers of neurons due to the computational complexity of the training process. But since the early 2000s deep neural networks consisting of many layers have been possible, and are now used for tasks that vary from pre-screening job applications to revolutionary approaches in health care.
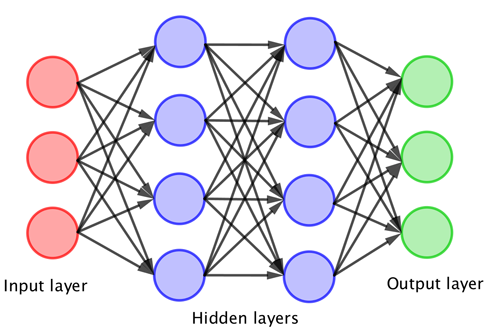
The typical architecture of a neural network – the more layers that you have the "deeper" network.
Deep learning is increasingly important in many areas both outside and inside science. Its usefulness has been proven, but there still are a lot of unanswered questions about the theory of why such deep learning approaches work. You can find out more about the successful applications and cutting-edge research in deep learning on Plus.
This article is based in part on Chris Budd's excellent article What is machine learning?, and on our package Learning the mathematics of the deep, produced as part of our collaboration with the Isaac Newton Institute for Mathematical Sciences.
Return to the Plus advent calendar 2022.
This article was produced as part of our collaboration with the Isaac Newton Institute for Mathematical Sciences (INI) – you can find all the content from the collaboration here.
The INI is an international research centre and our neighbour here on the University of Cambridge's maths campus. It attracts leading mathematical scientists from all over the world, and is open to all. Visit www.newton.ac.uk to find out more.