
Machine learning: Is it ethical?
This article is based on a talk in Chris Budd's ongoing Gresham College lecture series. You can see a video of the talk below and see other articles based on the talk here.
Machine learning algorithms are now finding their ways into numerous applications, some with very significant impact on human society. Some of the less controversial applications involve placing adverts on the Internet, speech recognition, text recognition, image captioning, automatic translation, short term weather forecasting, and image recognition and classification (including faces). The algorithms are also used in spam filters, automatic cars, and by banks to detect fraud.

Speech recognition, as used by the personal assistant in your phone, uses machine learning.
The algorithms become controversial, however, when they directly affect human beings and their lives. Examples of this include the use of machine learning by insurance companies to determine premiums, by supermarkets to target potential customers, by companies to shortlist for jobs, and by the US justice system to decide on prisoner sentencing. We will illustrate this with two more detailed examples.
Retirement payments
The consultancy firm Accenture did a survey and found that 68% of global consumers would be happy to use computers to give them advice to plan for retirement, with many feeling it would be faster, cheaper, more impartial, less judgemental and "less awkward" than human advice.
In this approach machine learning algorithms are used to analyse a person's financial situation. The client is first asked questions online about their income, expenses, family situation and attitude to risk. The algorithm then works out an appropriate investment plan with a mix of investments, from index funds to fixed-income bonds. These algorithms also incorporate personal information such as the age of the client. The market research company Statista says the US market will grow 29% per year between now and 2021, and forecasts that the number of Chinese investors using machine learning algorithms will jump from two million to nearly 80 million in the same period.
Medical diagnosis and treatment
Neural nets are now used in medical diagnosis, drug design, biochemical and image analysis. Convolutional neural nets (CNNs) have been used in drug discovery. In 2015, the company Atomwise introduced AtomNet, the first deep learning neural network for structure-based rational drug design. The system trains directly on three-dimensional representations of chemical interactions. AtomNet was used to predict novel candidate biomolecules for multiple disease targets, most notably treatments for the Ebola virus and multiple sclerosis.
X-ray images could in future be assessed by machines.
Another use of machine learning in diagnosis is in the study of X-rays images. Techniques such as MRI lead to wonderfully clear images which can be used for a clear diagnosis. However, these methods take time to use. In certain cases of acute medical conditions, such as a knee or hip joint fractures, there is very limited time to make a diagnosis. Sophisticated imaging is not possible in this time, and doctors have to rely on standard X-rays, and they have to make a rapid assessment based on these.
Furthermore, the right expertise to make a diagnosis may not be immediately available. In this case machine learning can certainly help with the diagnosis. At the University of Bath Richie Gill and Ellen Murphy are pioneering a new method of machine diagnosis in which a CNN is trained on a set of X-ray images of hip joints with identified location and fracture type. The CNN can then be used on a new image to both identify the joint and to classify the types of fracture.
Is it ethical, reliable and legal?
Deep neural networks are VERY black boxes! As we have seen, you train them by feeding them a large amount of data. They then apply complex, and hard to analyse, optimisation methods to determine their inner architecture. The networks are used to make decisions on complex problems, which have a direct effect on people's lives. In the case of chess this works and appears to have no ethical problems, but can we really justify the use of machine learning in the case of vetting job applications, or other similar issues?
I believe, amongst many others, that the answer must be no. Here are some reasons for this.
Correlation does not imply causation
This is a classical issue in statistics. If you have a large amount of data and then compare one set of data against another you may well find examples which seem to be linked. In the following we compare science spending in the USA with the number of suicides. They appear to be closely linked. We might conclude from this graph (and a machine learning might well deduce) that suicides go up with science spending. Thus the US should immediately reduce science spending to cut down on the number of suicides in the country.
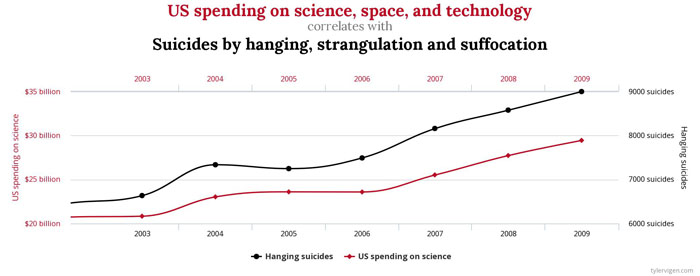
Correlation does not imply causation. Chart: Tylervigen.com, CC BY 4.0.
The reason why this is nonsense is that changes in one set of data do not necessarily cause changes in the other. In the example above it is much more likely that other changes in the US, such as a rise in GDP, lead both to a rise in suicides and in science funding. The more random sets of data that you look at, the more likely it is that you will find false correlations between them. Or more poetically "you can find anything you look for in the clouds". Be warned, this process had led to serious miscarriages of justice!
Statisticians are well aware of this problem and have tests to prevent making false deductions. Machine learning used carelessly may have no such tests. We have little guarantee that a machine learning algorithm may not draw false conclusions from a large training set.
Machine learning can make mistakes
Not only are machine learning algorithms far from perfect, they do not come with any estimate of the uncertainty of their predictions.
One of the uses of machine learning is in the design and operation of automatic cars. Clearly such a car must be able to detect, identify, and recognise the meaning of standard road signs. In a recent study, however, a machine learning algorithm trained on a set of road signs identified an image of a stop sign that had been slightly defaced as a 45mph speed sign! Fortunately this wasn't used in a real application.
Machines aren't humans
Another issue with machine learning is implicit in the title. It is learning by machines. Humans and machines do not always "think" in the same way. To illustrate this I will look briefly at the problem of perception. This is important in the area of machine vision in which a robot views its environment and makes decisions about what it sees. Clearly we would want the robot to see things in the same way that humans do. However, this may not be possible. An illustration of this is given by the checker shadow illusion illustrated below.
Have a look at this picture and decide for your self which of the two squares A and B is the brightest.

Which square is brighter. Image: Edward H. Adelson.
{kind=link}
It may surprise you to know that in fact they are equally bright! Our human brains compensate for the shadow of the cylinder by making square B appear to be brighter than square A. This is how humans see things. However a computer will see this differently, as from a simple measurement squares A and B are exactly as bright as each other.
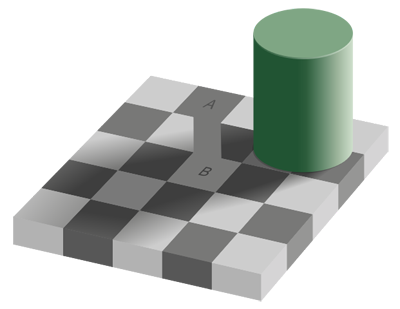
They are both equally bright! Image: Edward H. Adelson.
No doubt there are many other examples where machines and humans think differently — we shouldn't expect them to think the same.
Implicit bias
We might think that one of the advantages of a machine learning approach to the selection of job applicants (along with other human related issues) is that, unlike humans, they do not show bias. However, this is certainly not the case. When we train a neural network on say a set of CVs the training set of data itself contains all of the biases of the original decision makers. These biases will be absorbed into the inner workings of the machine learning algorithm. This behaviour has certainly been found to exist in such trained machines. However, unlike with a human operator, it is harder to identify reasons for this. Before using such a machine learning method it is essential that the training set is carefully tested for bias in advance of it being used to train a machine. But how can we guarantee or enforce this?
Conclusion
The above shows that we should not necessarily trust a machine learning algorithm. It is evidently not ethical to use a machine to make decisions when we do not trust it for making good decisions. Even if we trust a machine learning system, such as in the chess playing algorithms, there are still significant ethical issues in the way that they are used.
For example, now it is possible to carry a computer in your pocket, which can beat a grand master at chess, the temptations of cheating have become too great for many to bear. As a result we have seen a significant rise in the amount of cheating in these games mostly by finding ways of looking at the computer without anyone else noticing. To counter this there has also been a lot of progress in the detection of cheats. My friend Ken Regan at the University of Buffalo, NY (and a mathematical logician), is a world expert in detecting chess cheats, which he does using sophisticated statistical methods.
The ethical issues involved in machine learning are so great that my university at Bath held a special semester this year, devoted just to these topics, with a big public debate at the end. One question that looms large is whether and how machine learning will replace jobs currently done by humans and how this will effect society. I am particularly interested in whether machines will one day replace mathematicians. That's what we will look at in the next article.
About this article
This article is based on a talk in Budd's ongoing Gresham College lecture series (see video above). You can see other articles based on the talk here.

Chris Budd.
Chris Budd OBE is Professor of Applied Mathematics at the University of Bath, Vice President of the Institute of Mathematics and its Applications, Chair of Mathematics for the Royal Institution and an honorary fellow of the British Science Association. He is particularly interested in applying mathematics to the real world and promoting the public understanding of mathematics.
He has co-written the popular mathematics book Mathematics Galore!, published by Oxford University Press, with C. Sangwin, and features in the book 50 Visions of Mathematics ed. Sam Parc.