
Robots to play games with
This article is based on a talk in Chris Budd's ongoing Gresham College lecture series. You can see a video of the talk below and see other articles based on the talk here.
The ability of computers to play games such as chess and go, which have a well-defined set of rules and an almost infinite level of variation of play, has long been considered to be a test (and a stimulus) for the development of weak artificial intelligence (see the last article for a definition).

Alan Turing
Earlier, and in perhaps the earliest example of weak AI, three of the pioneers of the electronic computer, Alan Turing, John Von Neumann, and Claude Shannon had asked themselves whether a machine can be made to think like a person, and considered this in the context of whether a machine could be made to play chess. Turing began the investigation of chess playing computers with a system written out with paper and pencil, where he played the role of the machine. In 1949 Shannon extended Turing's work, explaining about his interest in chess that, "Although of no practical importance, the question is of theoretical interest, and it is hoped that [...] this problem will act as a wedge in attacking other problems — of greater significance."
The approach used by Shannon, and those that came after him, was to attempt to program a computer using strategies related to the way that humans themselves play chess. Shannon distinguished between type-A and type-B search strategies for playing computer chess. Type-A searches employed a brute-force algorithm that searched all positions equally, all the way to the limits of computability. Shannon thought type-A strategies were impracticable due to the limitations of computers at that time. In addition they were too simple as they pursued all options rather than following promising strategies in depth.
Shannon suggested that type-B search strategies should be used instead. These would use one of two approaches: either employing some type of search which only pursued promising strategies, or evaluating only a few known good moves for each position. The latter case involves ignoring all moves but those determined to be good (this is also called forward pruning). In practice, however, modern chess playing computers use the first approach—they weight some sequences of moves more heavily than others, and employ a quicker cut-off for less promising sequences.

Claude Shannon playing with his electromechanical mouse Theseus, one of the earliest experiments in artificial intelligence. (Image Copyright 2001 Lucent Technologies, Inc. All rights reserved.)
Since Shannon's work chess programs were developed along very much the lines that he suggested and quickly became as good as humans. A major breakthrough came in 1996 when the chess playing code Deep Blue was able to beat the world champion Grand Master Garry Kasparov. Notably Deep Blue could evaluate 200 million positions a second.
More recently the "ultimate" chess playing program based on Shannon's ideas was the code Stockfish which could beat any human player. The perfect chess programme had arrived ... or had it? At the end of 2017 everything changed again in a breakthrough for machine learning. The team at Google Mind developed AlphaZero which was a huge (and highly computing intensive) deep learning neural net based machine learning algorithm. They then gave it the rule book of chess and no other information about the game. AlphaZero then played against itself for many hours, learning its chess strategies purely from playing and with no direct human input.
Following this AlphaZero took on Stockfish and decisively beat it with a score of 28 wins, 72 draws, and no losses! A measure of the quality of these programmes is its ELO rating which measures the level of play. Stockfish has an ELO of 3226, AlphaZero is approaching an ELO of 3500, whereas the top human rating is 2800. The graph below shows that if a short time only is allowed for a move then Stockfish will win. However, give the computer 10 seconds per move and AlphaZero wins every time.
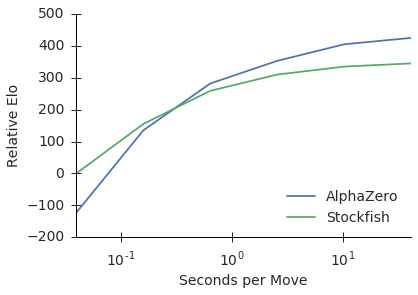
The ELO ratings of AlphaGo and Stockfish and their dependence on how much time there is to make a move. This graph is from the paper Mastering chess and shogi by self-play with a general reinforcement learning algorithm by D Silver et al.
A similar approach was used in 2016 to develop the go-playing computer AlphaGo Zero. Like AlphaZero, this had no input other than the rules of go and some symmetry properties of the board. From round-the-clock self-play it soon acquired the ability to outplay go grand master Lee Se-dol. We are now even looking at machines which can play poker, and even scrabble.
General machine learning
So, what is the technology that made AlphaZero and AlphaGo possible, where did it come from, and where is it heading? The idea of programming a computer to do a specific task goes back to the original concept of a computing machine. One of the earliest pioneers of this was Alan Turing who, in the 1930s came up the concept of the Turing machine. This very simple device could, in principle, be programmed to accomplish very complex tasks.
From this basic idea Turing and others in England such as Tommy Flowers and also John Von Neumann built the first programmable electronic computers. This progress all occurred during world war II. The motivation behind Turing and Flowers' work was the very specific task of breaking the various codes used by the Germans and this led to the Colossus computer. Similarly Von Neumann was motivated by the specific task of designing the atomic bomb, and this led to the ENIAC and MANIAC computers.

The Colossus Mark 2 computer was used to break German codes during WWII.
After the war Turing and others continued to work on the development of computers that could be programmed to do general tasks. Since then we have seen an explosive growth in computer technology and also in the algorithms and languages used to program computers. (My own area of research is closely related to this.) This growth continues at an exponential rate, with Moore's law predicting that computer power doubles every two years.
Until fairly recently the programs used to control a computer were typically written by a human computer programmer. They are usually written in a high level language such as C or Python or similar, and are then converted (compiled or interpreted) into the machine code instructions used by the computer architecture. Such coding is prone to errors (computer bugs) and the code often has to be extensively tested to ensure that it does not contain bugs on its release. As most of us will be only too aware, this testing is not always perfect.
More recently, there has been an important advance in the creation of provable codes and automated reasoning. In these codes an operation is specified by the programmer, but code is written by a machine in such a way that it can be proven no to contain errors. Provable codes have very important uses in the design of software in safety critical systems, such as the control for the jet engine in an airliner, medical devices and cyber security systems.
The most recent development in computer programming, however, has been the development of machine learning. We will have a look at this revolutionary technique in the next article.
About this article
This article is based on a talk in Budd's ongoing Gresham College lecture series (see video above). You can see other articles based on the talk here.

Chris Budd.
Chris Budd OBE is Professor of Applied Mathematics at the University of Bath, Vice President of the Institute of Mathematics and its Applications, Chair of Mathematics for the Royal Institution and an honorary fellow of the British Science Association. He is particularly interested in applying mathematics to the real world and promoting the public understanding of mathematics.
He has co-written the popular mathematics book Mathematics Galore!, published by Oxford University Press, with C. Sangwin, and features in the book 50 Visions of Mathematics ed. Sam Parc.